数据基础
机器学习涉及很多数据和统计学方面知识, 这里了解几个简单的术语
数据类型
数据可以分为分类数据和数值数据
- 分类数据(categorical data):反映事物类别的数据。如人按性别分为男、女两类。分类数据又可以分为无序数据和和有序数据。无序数据顾名思义,就是数据没有顺序关系,比如男,女。有序数据就是数据有大小顺序关系,比如小,中,大。
- 数值数据(numerical data):数值形式的数据,比如一组青少年的身高体重,某人一个月的成绩等等。数值数据又可以分为离散数据和连续数据。
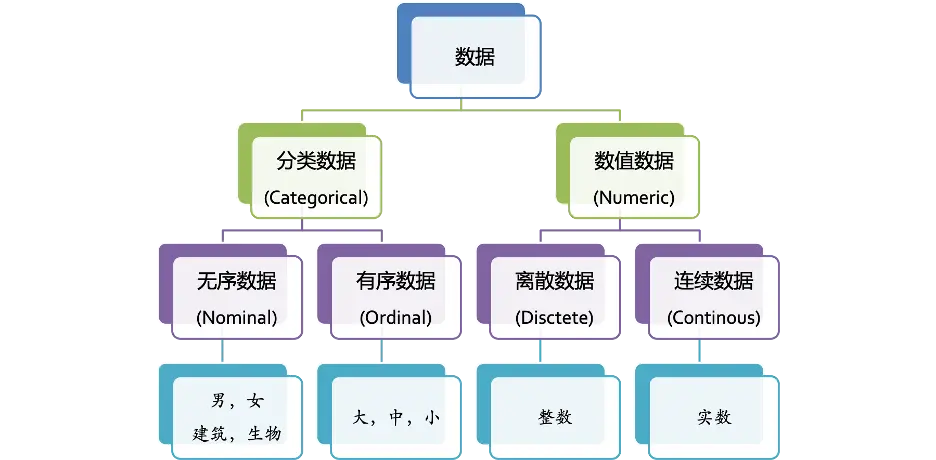
在实际机器学习项目中,我们遇到的很多是数值数据,也会有很多分类数据。
基本统计学术语
平均值
平均值(mean)是统计学中的一个重要概念,是集中趋势最常用的测度值,目的是确定一组数据的均衡点。平均值可能是我们最熟悉的一个统计值之一,比如我们经常会在新闻中看到平均工资,平均价格等。因为用平均值表示一组数据的情况,有直观、简明的特点,所以在日常生活中经常用到。 但是平均值又是一个经常错误使用的统计值。假设我们班有49个人,有一天转来一个新生,是李嘉诚家族的一个小孩。如果计算我们班同学的平均资产,这个任务就变得没有什么意义了,因为大家都被平均了。再举一个例子,统计学家最喜欢举的关于平均值例子可能就是“男人和女人平均有一颗睾丸” ,但这是个正确但毫无意义的平均值。
或者是这里所有人的平均身高有什么意义呢?

期望
期望可以简单认为就是平均值。
中位数
中位数(median)代表一个数据集中的一个数值,它可将数据集划分为长度相等的上下两部分。对于有限的数据集,可以通过把所有观察值高低排序后找出正中间的一个作为中位数。如果观察值有偶数个,则中位数不唯一,通常取最中间的两个数值的平均数作为中位数。对于一组有限个数的数据集来说,其中位数是这样的一种数:这群数据的一半的数据比它大,而另外一半数据比它小。
计算有限个数的数据的中位数的方法是:把所有的同类数据按照大小的顺序排列。如果数据的个数是奇数,则中间那个数据就是这群数据的中位数;如果数据的个数是偶数,则中间那2个数据的算术平均值就是这群数据的中位数。 还以我们班转来李嘉诚家族的一个小孩为例,根据中位数可以发现,他在不在我们班对中位数的影响很有限。所以中位数能够有效避免数据被平均的问题。
现在, 这里所有人的身高中位数就有意义了吧?
标准差
标准差(Standard Deviation),数学符号 $\sigma$,在概率统计中最常使用作为测量一组数值的离散程度之用。
正态分布
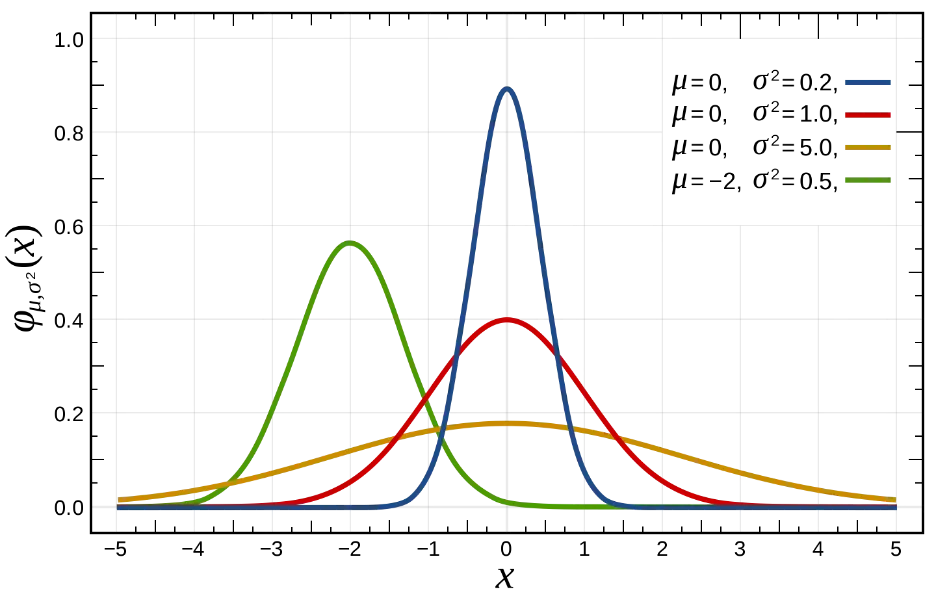
正态分布(normal distribution)又名高斯分布(Gaussian distribution),是一个非常常见的连续概率分布。正态分布在统计学上十分重要,经常用在自然和社会科学来代表一个不明的随机变量。在下图中,$\mu$ 是期望,$\sigma^2$ 是方差,图示就是不同期望与方差情况下的正态分布图。其中期望为 0,方差为 1 的情况就是标准正态分布。
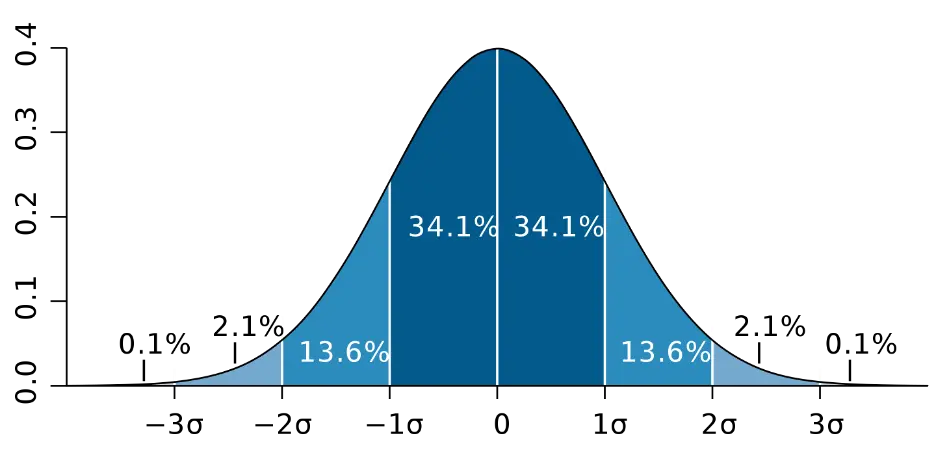
从下图可以看出标准差在正态分布中的体现。约 68% 数值分布在距离平均值有 1 个标准差之内的范围,约 95% 数值分布在距离平均值有 2 个标准差之内的范围,以及约 99.7% 数值分布在距离平均值有 3 个标准差之内的范围。称为“68-95-99.7法则”。
反馈问题
文档有问题? 或者有其他意见和建议? 请在本文档的 Github 仓库直接反馈
点我反馈进入反馈页面不知道如何反馈, 请点击这里