
层次聚类与探索性数据分析
我们将通过层次聚类进行聚类分析。我们使用了众所周知的鸢尾花 (iris) 数据集,其中包含 150 个鸢尾花,每个花都属于三种物种(setosa,versicolor 和 virginica)之一。
在未经训练的人看来,这三个物种非常相似,那么我们如何最好地区分它们呢?数据集包含萼片和花瓣尺寸(宽度和长度)的度量,并且我们假设这些度量会引起有趣的聚类。但是,是这样吗?
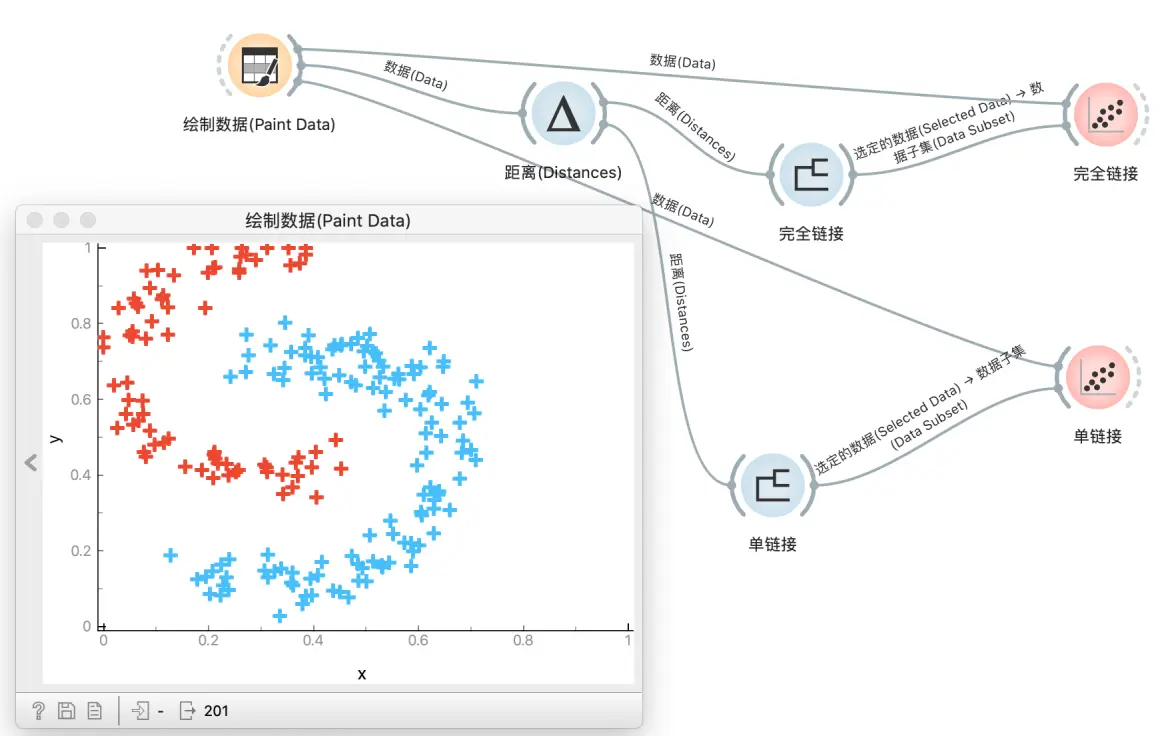
层次聚类工作流程
为了找到聚类,我们将数据从文件小部件中输出到距离小部件,然后输入进层次聚类。我们工作流程中的最后一个小部件可视化了层次聚类树状图。在树状图中,让我们用相应的鸢尾花种类(Annotation = Iris)注释分支。我们看到并不是所有的类都由相同的实际类组成-有些混合类既有 virginicas 也有 versicolor。
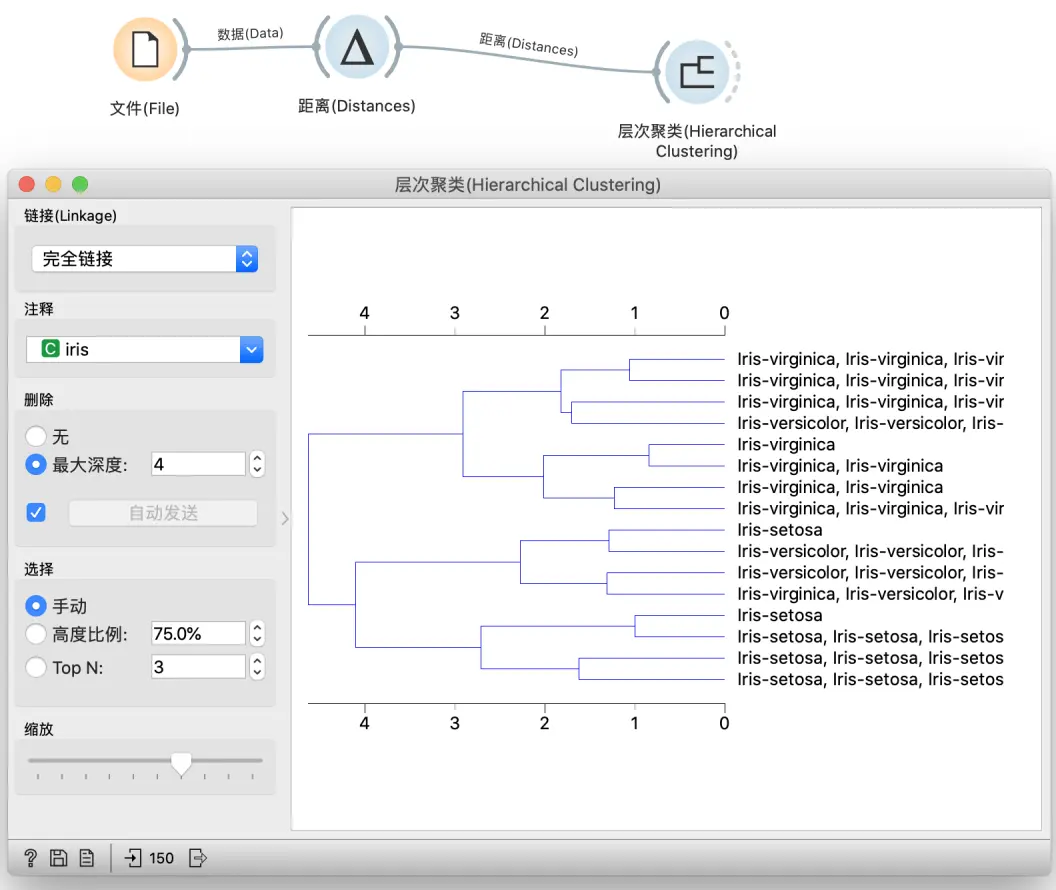
数据表中观察
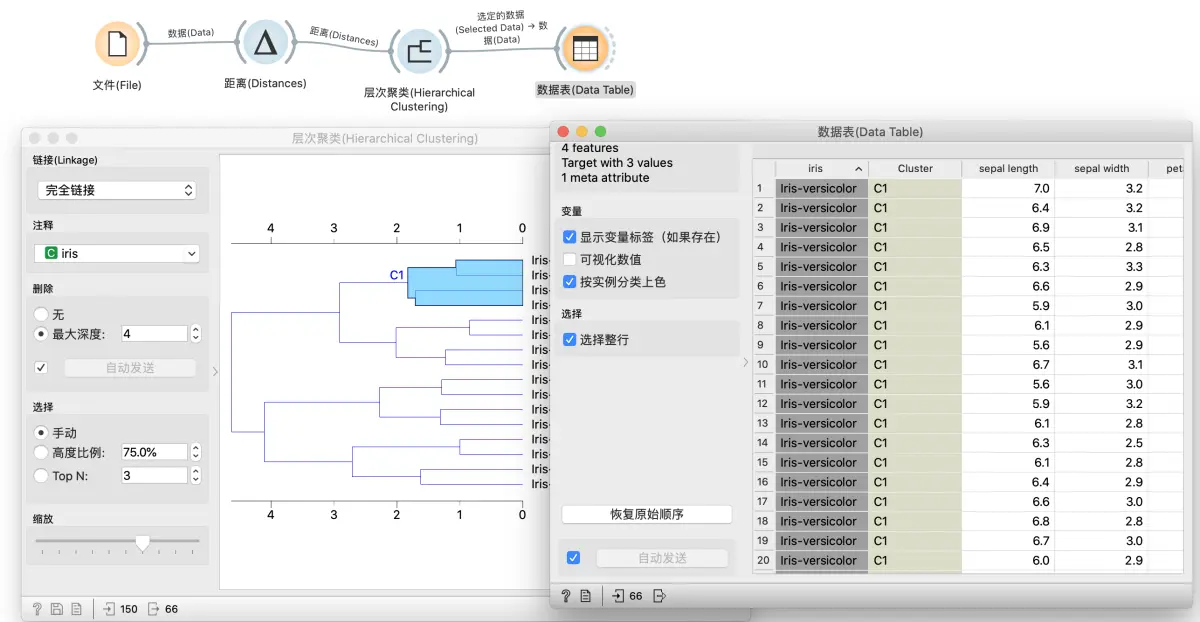
要查看这些聚类的效果, 我们可以在数据表观察. 将层次聚类的输出 选定的数据 输入数据表, 选中层次聚类中的某分支, 在数据表观察. 为了更容易发现问题, 我们可以点击表头, 按照 iris 排序, 可以发现这里有两种不同的类别.
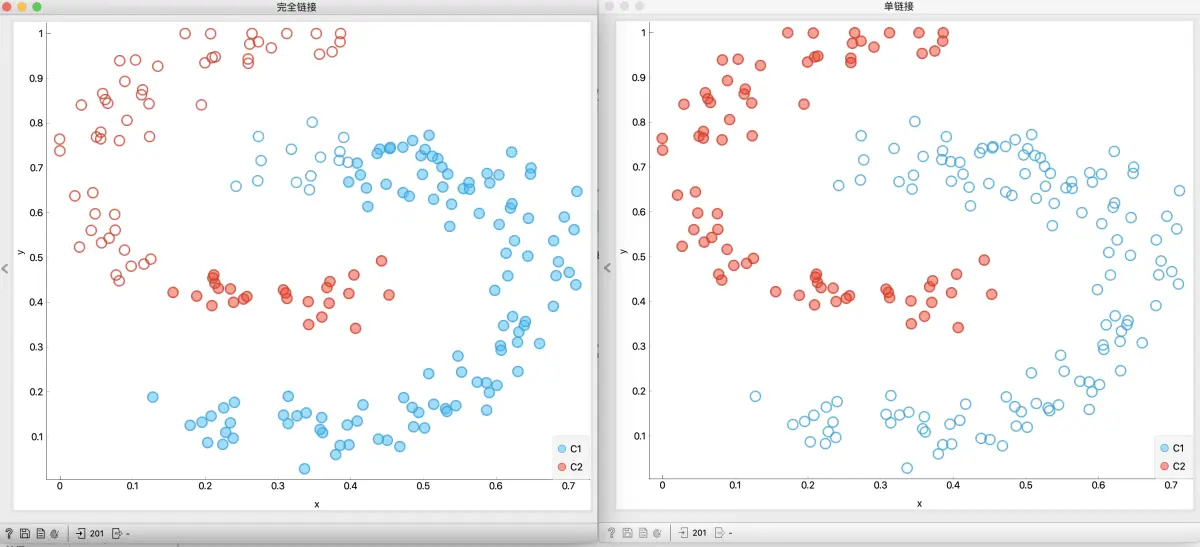
散点图中观察
还可以在散点图更方便地可视化.
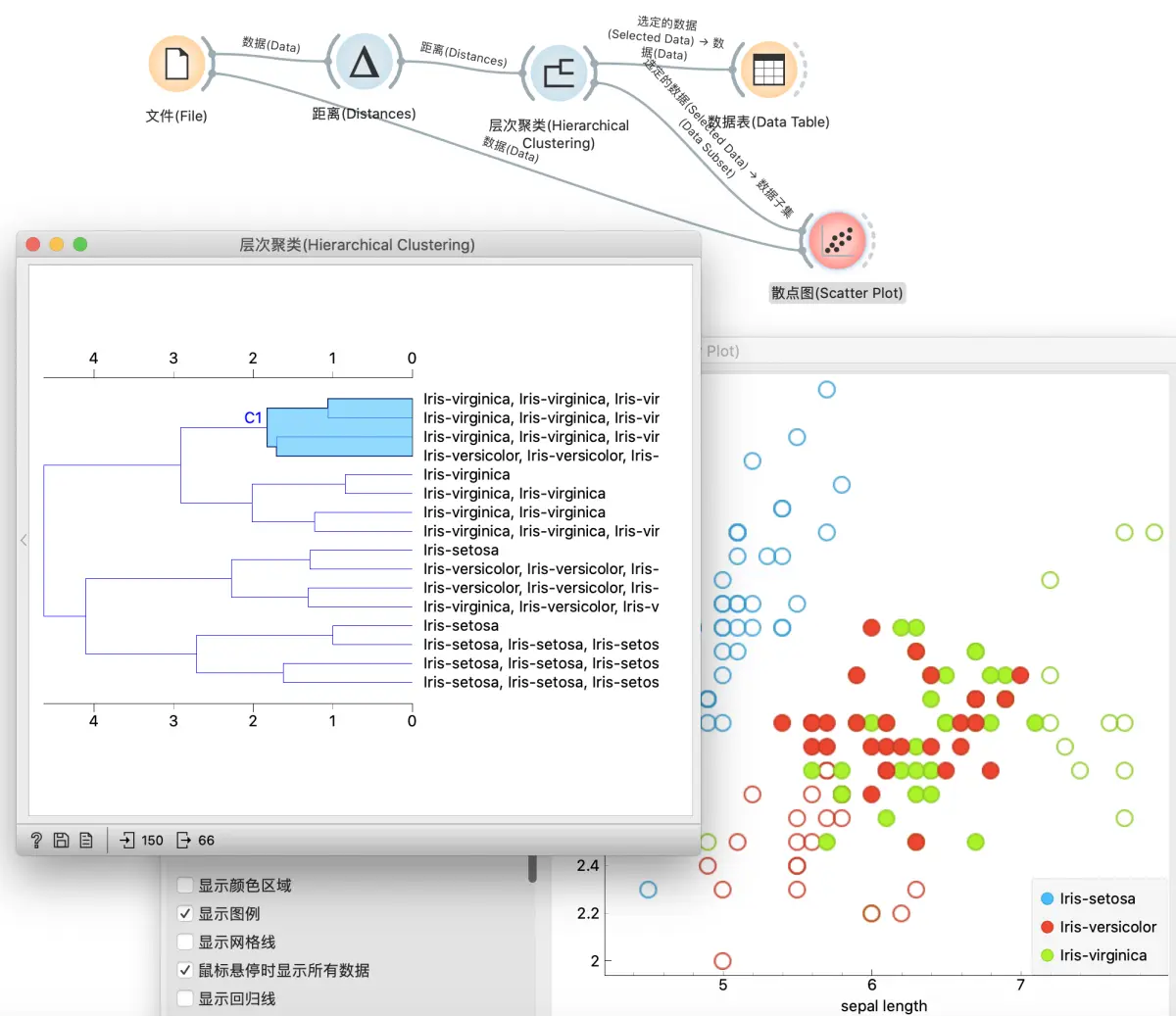
将数据从文件输入到散点图, 同时将层次聚类的输出 选定的数据 输入散点图的 ‘数据子集’. 在图中, 空心圈是所有数据, 实心圈是我们在层次聚类选中的数据. 可以发现, 这个聚类的效果很一般.
通过无监督学习小部件和可视化的小部件的组合,可以进行有趣的探索性数据分析。
反馈问题
文档有问题? 或者有其他意见和建议? 请在本文档的 Github 仓库直接反馈
点我反馈进入反馈页面不知道如何反馈, 请点击这里
留下评论