距离(Distances)
计算数据集中行/列之间的距离。
输入
- 数据:输入数据集
输出
- 距离:距离矩阵
功能
距离(Distances) 小部件可计算数据集中行或列之间的距离。默认情况下,将对数据进行归一化以确保平等对待各个特征。 归一化总是按列进行。
稀疏数据使用 Euclidean,Manhattan 和 Cosine 度量
可以将生成的距离矩阵进一步发送到层次聚类(Hierarchical Clustering)以发现数据中的组,再发送到距离图(Distance Map)或距离矩阵(Distance Matrix)以可视化距离( 对于较大的数据集,距离矩阵可能会非常慢),发送到MDS以使用距离矩阵映射数据实例,最后将其保存为保存距离矩阵(Save Distance Matrix)。 可以使用距离文件(Distance File)加载距离文件。
界面
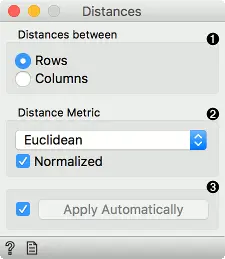
- 选择是测量行还是列之间的距离。
-
选择 距离度量
- Euclidean: 两点之间的直线距离
- Manhattan: 所有属性的绝对差之和
- Cosine: 内积空间的两个向量之间的夹角的余弦
- Jaccard: 交集的大小除以样本集并集的大小
- Spearman: 值的秩之间的线性相关性,重新映射为[0,1]之间的距离
- Spearman absolute: 值的秩的绝对值之间的线性相关性,重新映射为[0,1]之间的距离
- Pearson 值之间的线性相关性,重新映射为[0,1]之间的距离
- Pearson absolute 值的绝对值之间的线性相关性,重新映射为[0,1]之间的距离
- Hamming: 相应值不同的特征数量
- Bhattacharyya distance: 两个概率分布之间的相似度,不是真实距离,因为它不服从三角形不等式。 归一化特征。 归一化总是按列进行。值以零为中心并缩放。 在有缺失值的情况下,小部件会自动填充行或列的平均值。 该小部件可用于数字数据和分类数据。 对于分类数据,如果两个值相同(“绿色”和“绿色”),则距离为0;如果两个值不同(“绿色”和“蓝色”),则距离为1。
- 勾选 自动应用 以自动将更改提交到其他窗口小部件。 或者,按 应用。
示例
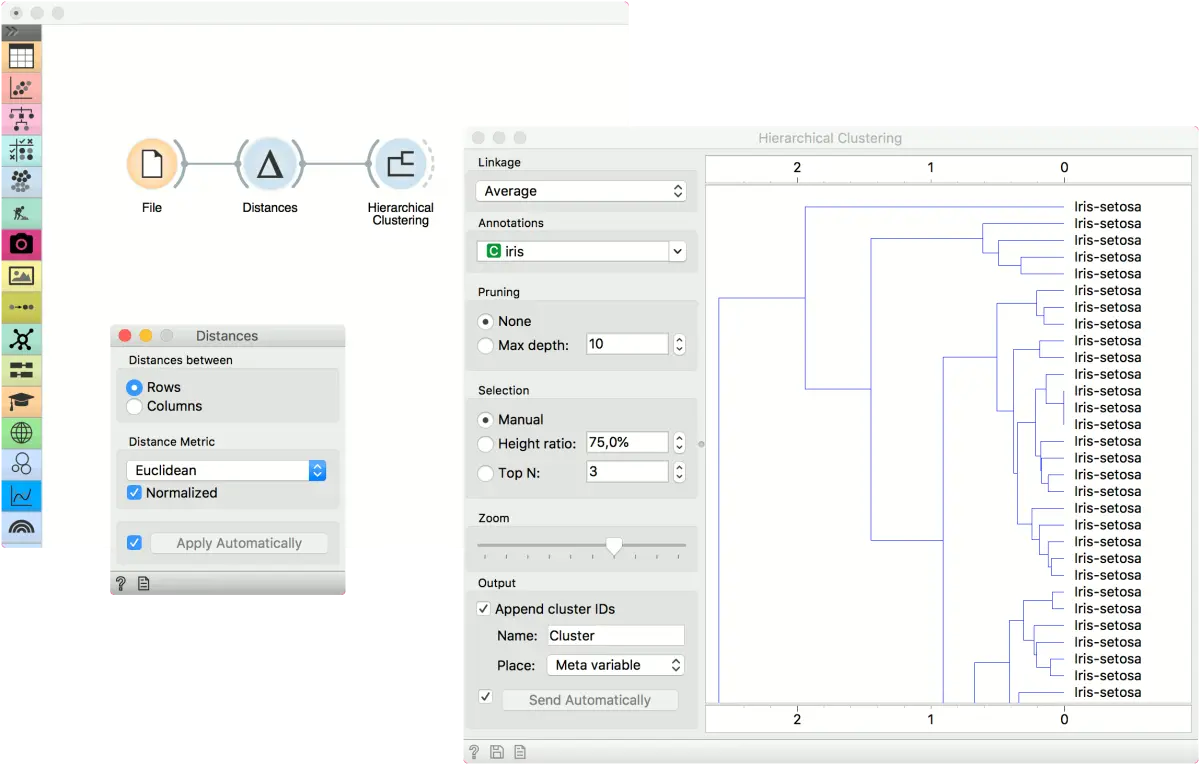
第一个示例显示了距离(Distances) 小部件的典型用法。 我们使用文件(File)小部件中的 iris.tab 数据。 我们计算数据实例(行)之间的距离,并将结果传递给层次聚类(Hierarchical Clustering)。 这是查找数据实例组的简单工作流程。
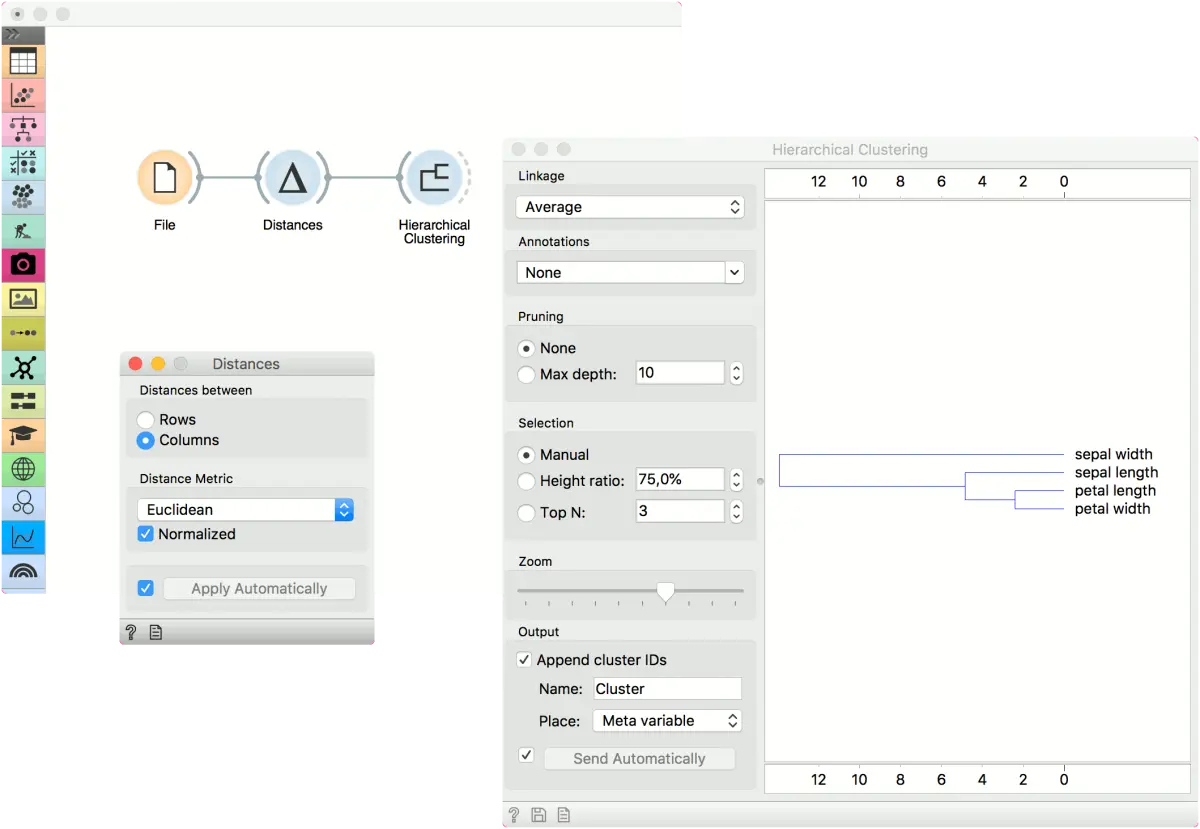
另外,我们可以计算列之间的距离,并发现我们的特征有多相似。
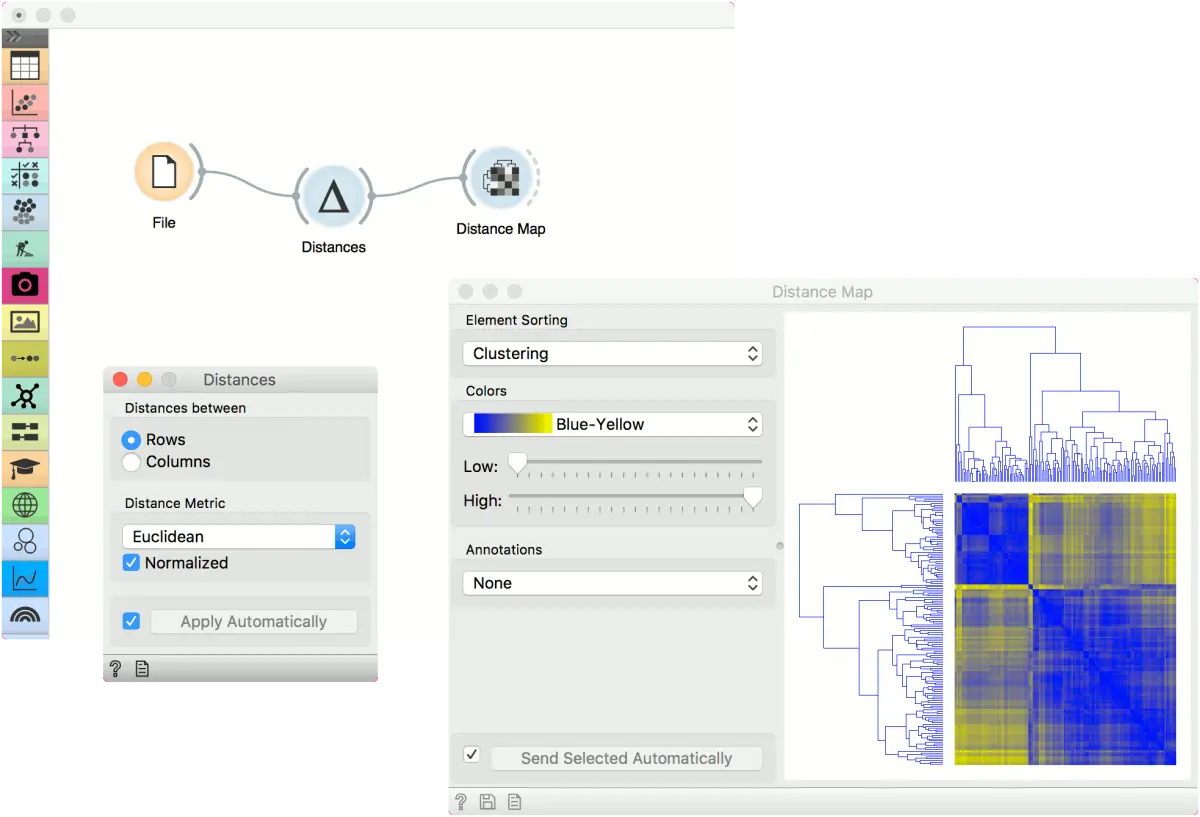
第二个示例显示如何可视化所得距离矩阵。观察数据相似性的一种好方法是在距离图(Distance Map)或MDS中。
反馈问题
文档有问题? 或者有其他意见和建议? 请在本文档的 Github 仓库直接反馈
点我反馈进入反馈页面不知道如何反馈, 请点击这里