随机化(Randomize)
将输入数据集的类别、属性和(或)元无序化
输入
- 数据:输入数据集
输出
- 数据: 随机化的数据集
功能
随机化(Randomize) 小部件在输入端接收数据集,并输出相同的数据集,但是其中的类、属性和(或)会被被随机排列。
界面
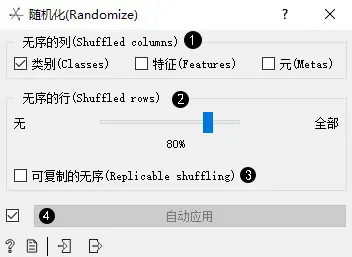
- 选择要混排的数据集的列将被如何分组。
- 选择要被混排的数据集的比例。
- 产生一个可以复制混排输出。
- 如果勾选了自动发送,则小部件会自动将更改传达给其他小部件。
示例
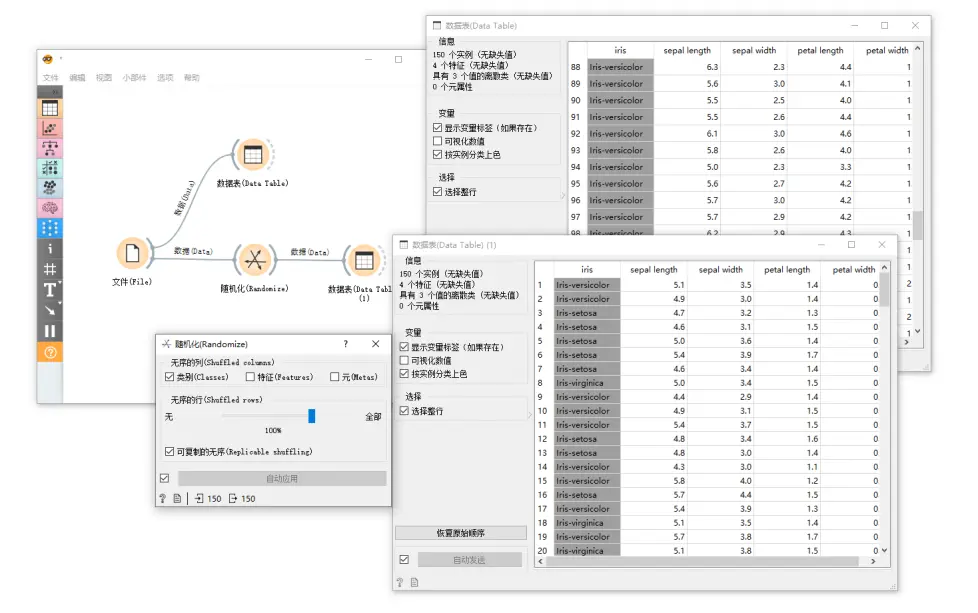
随机化(Randomize) 小部件通常放在数据输出之后(右)(例如文件(File)小部件)。下图示例展示了其基本用法,可以看到 iris 数据集的类变量值被随机排列了。
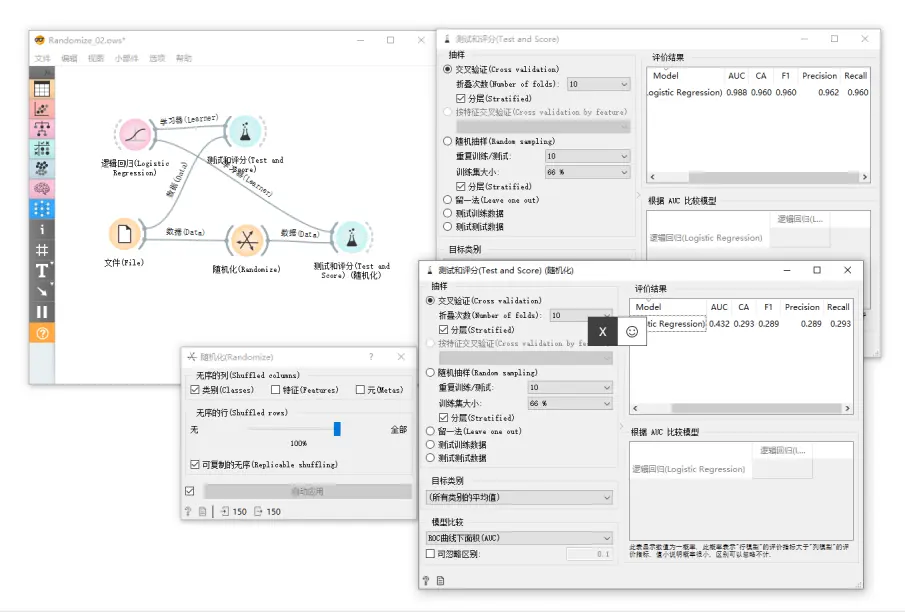
在下面的示例中,我们将演示对类变量值进行随机排列将会如何影响上面展示的同一数据集上模型的性能。
反馈问题
文档有问题? 或者有其他意见和建议? 请在本文档的 Github 仓库直接反馈
点我反馈进入反馈页面不知道如何反馈, 请点击这里