k 近邻(kNN)
根据最靠近的训练实例进行预测。
输入
- 数据:输入数据集
- 预处理器:预处理方法
输出
- 学习器:kNN 学习算法
- 模型:训练有素的模型
功能
k 近邻(kNN) 小部件使用kNN算法在特征空间中搜索k个最近的训练示例并将其平均值用作预测。
界面
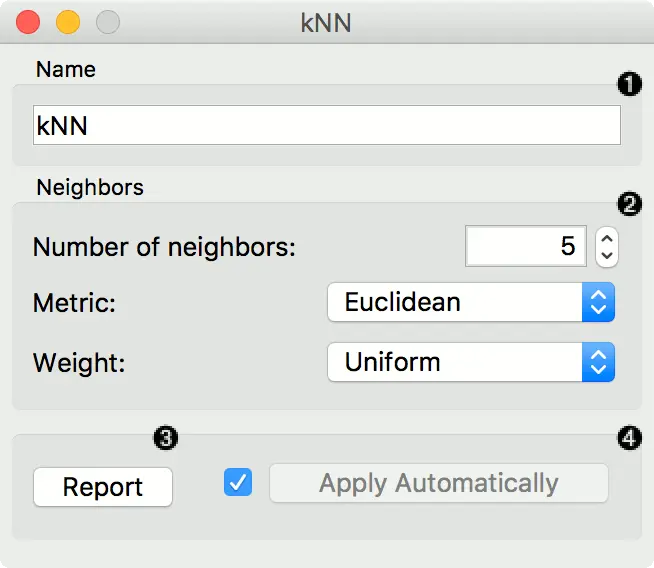
- 一个名称,该名称将出现在其他小部件中。 默认名称是“k近邻(kNN)”。
- 设置最近邻居的数量,距离参数(度量)和权重作为模型标准。
- 度量可以是:
- 欧几里得(“直线”,两点之间的距离)
- 曼哈顿(所有属性的绝对差之和)
- 最大值(属性之间的绝对最大差异)
- Mahalanobis(点与分布之间的距离)。
- 可以使用的 权重 是:
统一:每个邻域中的所有点均被同等加权。距离:查询点附近的邻居比远处的邻居影响更大。
- 度量可以是:
- 发送报告
- 勾选 “自动应用” 以自动传送对其他小部件的更改,并在连接学习数据后立即训练分类器。 或者,在配置后按 “应用”。
示例
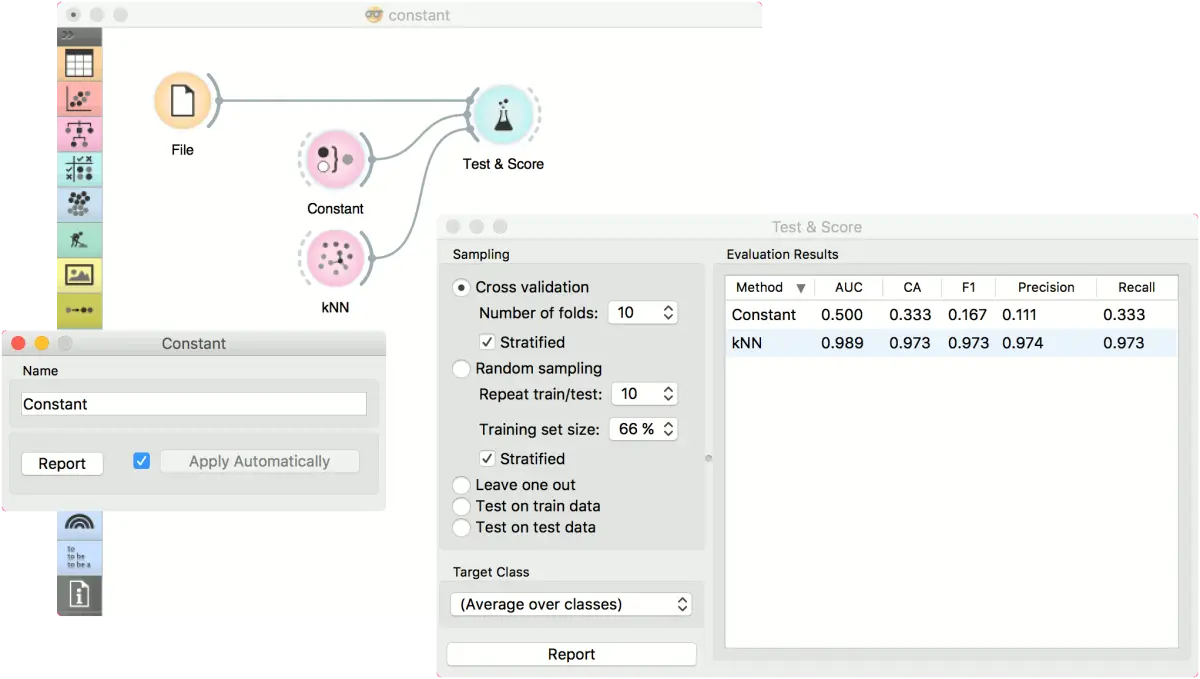
第一个示例是对 iris 数据集的分类任务。 我们将k 近邻(kNN) 的结果与默认模型常量预测(Constant)进行比较,该模型始终会预测多数分类。
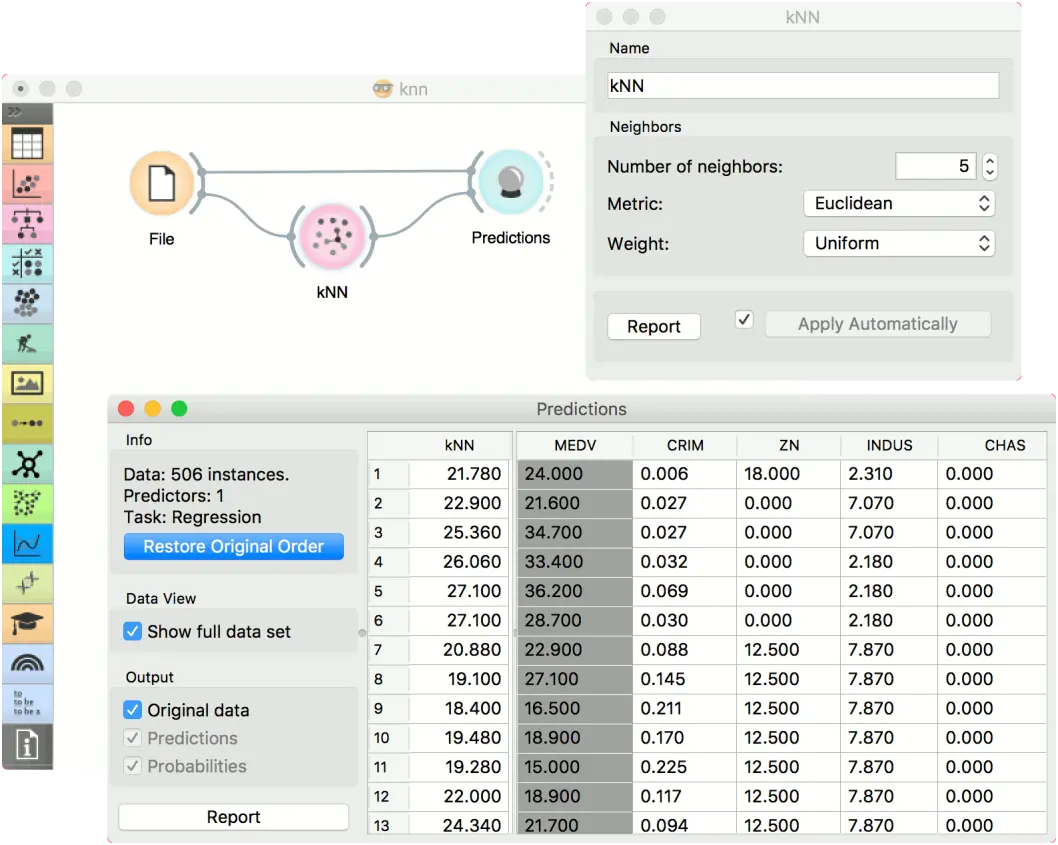
第二个示例是回归任务。 此工作流程显示了如何使用 k 近邻(kNN) 输出。 出于本示例的目的,我们使用了 housing 数据集。 我们将 k 近邻(kNN) 预测模型输入到预测(Predictions)中,并观察预测值。
反馈问题
文档有问题? 或者有其他意见和建议? 请在本文档的 Github 仓库直接反馈
点我反馈进入反馈页面不知道如何反馈, 请点击这里