层次聚类(Hierarchical Clustering)
使用层次聚类算法对项目进行分组。
输入
- 距离:距离矩阵
输出
- 选定的数据:从图中选择的实例
- 数据:带有附加列的数据,显示是否选择了实例
功能
该小部件从距离矩阵计算任意类型的对象的层次聚类,并显示相应的树状图。
界面
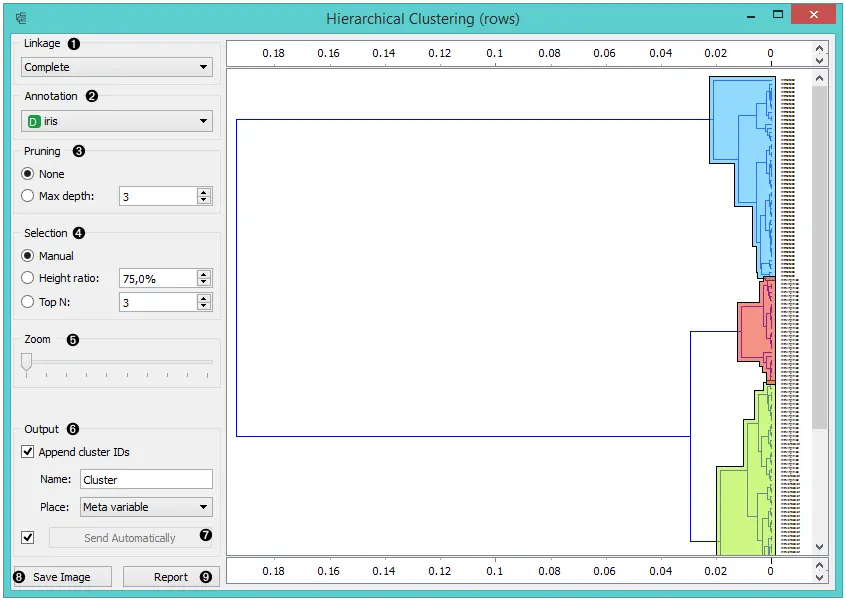
- 小部件支持四种测量聚类之间距离的方法:
单链接计算两个聚类的最接近元素之间的距离平均链接计算两个聚类元素之间的平均距离加权链接使用WPGMA方法完全链接计算集群最远元素之间的距离
- 可以在
注释框中选择树状图中节点的标签。 - 通过选择树状图的最大深度,可以在
剪枝框中修剪大的树状图。这只会影响显示,而不会影响实际的聚类。 - 小部件提供三种不同的选择方法:
手动: 在树状图内单击将选择一个聚类。按住Ctrl/Cmd可以选择多个聚类。每个选定的聚类以不同的颜色显示,并在输出中被视为一个单独的聚类。高宽比: 单击树状图的底部或顶部标尺会在图形中放置一条截断线。已选择该线右边的项目。Top N: 选择顶部节点的数量。
- 使用
缩放并滚动以放大或缩小。 - 如果要聚类的项目是实例,则可以为它们添加聚类索引(追加聚类ID)。该ID可以显示为普通的“属性”,“类属性”或“元属性”。 在第二种情况下,如果数据已经具有类属性,则将原始类放在元属性中。
- 可以在任何更改时自动输出数据(自动发送 已打开),或者,如果未选中此框,则可以通过按 发送数据 来输出。
- 单击此按钮将生成可以保存的图像。
- 生成报告。
示例
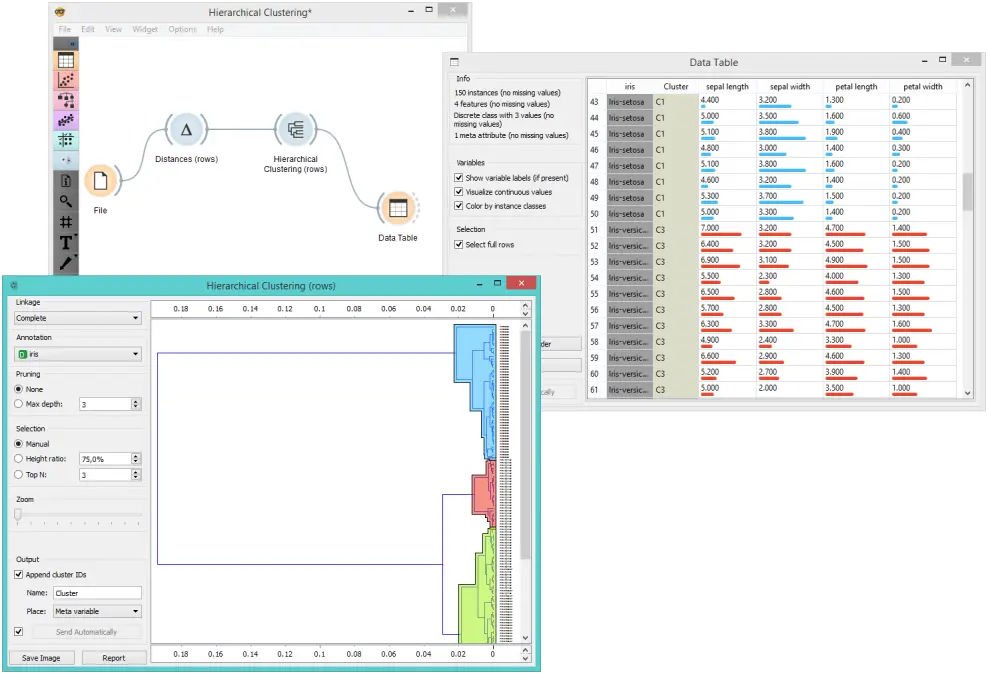
下面的工作流程显示了数据表(Data Table)小部件中 Iris 数据集的 层次聚类(Hierarchical Clustering) 的输出。 我们看到,如果在 层次聚类(Hierarchical Clustering) 中选择 追加聚类ID,我们可以在 数据表(Data Table) 中看到一个名为 Cluster 的附加列。 这是一种检查层次聚类如何聚合各个实例的方法。
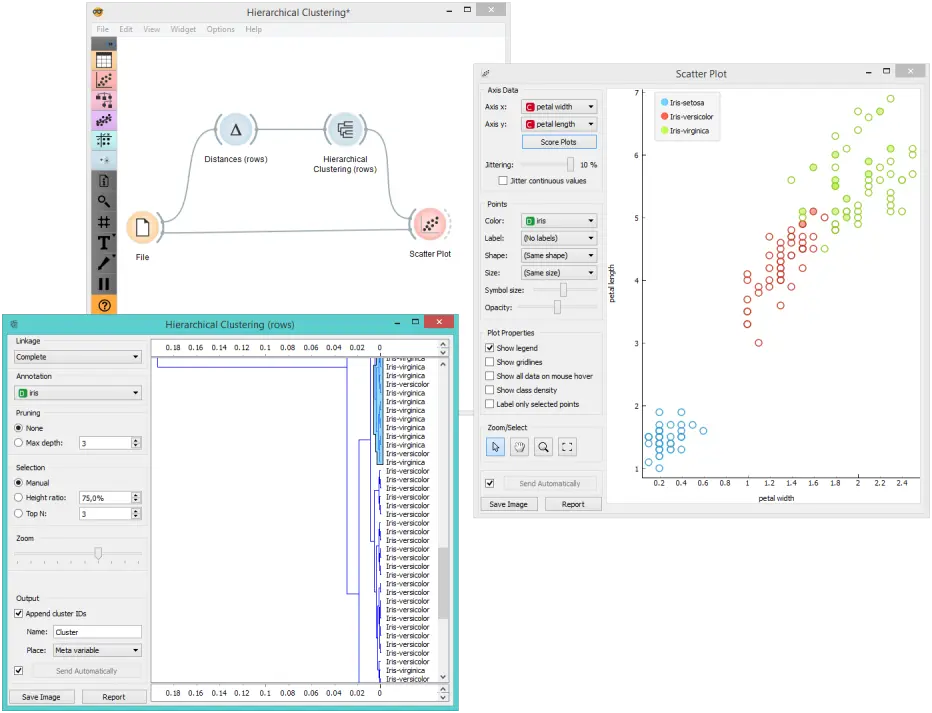
在第二个示例中,我们再次加载了 Iris 数据集,但是这次我们添加了散点图(Scatter Plot),显示了文件(File)小部件,同时接收来自 层次聚类(Hierarchical Clustering) 的选定实例信号。 这样,我们可以观察到所选聚类在投影中的位置。
反馈问题
文档有问题? 或者有其他意见和建议? 请在本文档的 Github 仓库直接反馈
点我反馈进入反馈页面不知道如何反馈, 请点击这里