列线图(Nomogram)
用于朴素贝叶斯和逻辑回归分类器。
输入
- 分类器:已训练的分类器
- 数据:输入数据集
列线图(Nomogram)
输出
- 特征:选定的变量,默认为 10
功能
列线图(Nomogram) 将朴素贝叶斯分类器和逻辑回归分类器可视化表示。它洞察训练数据的结构以及特征对分类概率的影响。除了可视化分类器之外,小部件还提供了对分类概率的预测的交互式支持。下面的截图显示了 Titanic 数据集的列线图,该图建模了乘客无法幸免于泰坦尼克号灾难的概率。
当绘制的数据集中的属性过多时,只能选择排名最高的属性进行显示。对于朴素贝叶斯表示,可以从“不排序”,“名称”,“绝对重要性”,“正面影响”和“负面影响”中选择,对于逻辑回归可以从“不排序”,“名称”和“绝对重要性”中进行选择 回归表示。
所选目标类别的概率是通过 “1-vs-all” 原理来计算的,在处理多类别数据时应将其考虑在内(替代概率不等于1)。为避免这种不便,您可以选择标准化概率。
界面
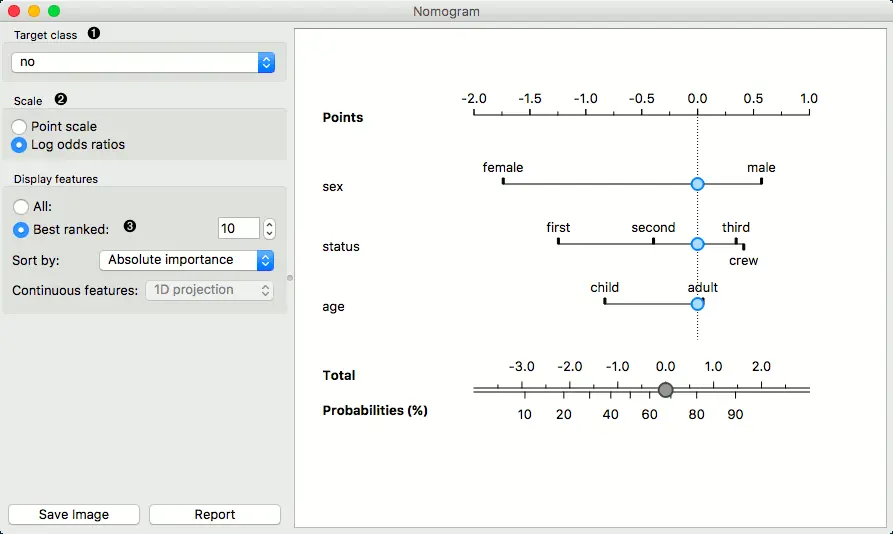
- 选择要为其建模概率的目标类别。选择是否要归一化概率。
- 默认情况下,小数位数设置为对数赔率。为了更容易理解和解释,可以使用 点刻度。 通过重新定标对数几率来获得单位,以使列线图(Nomogram) 中的最大绝对对数几率代表100点。
- 显示所有属性或仅显示排名最高的属性。 对它们进行排序并设置投影类型。
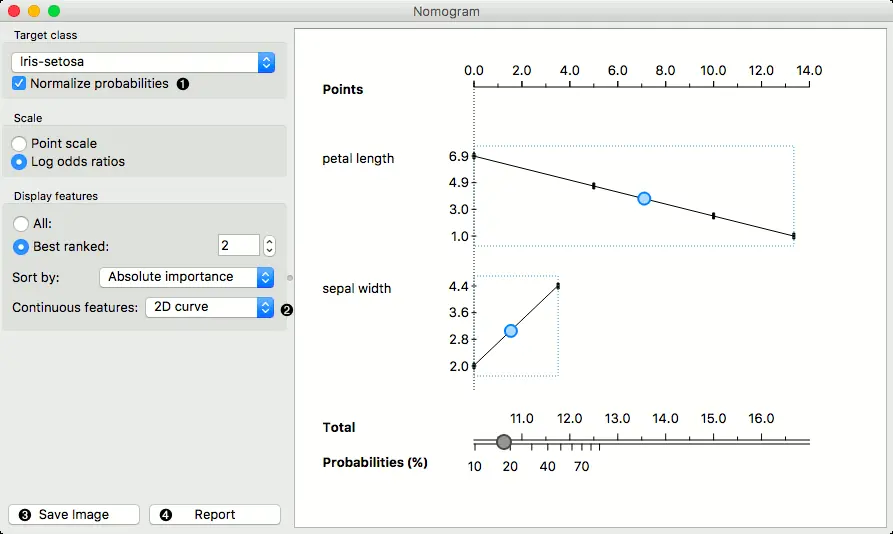
连续属性可以2D方式绘制(仅适用于Logistic回归)。
示例
第一个
列线图(Nomogram) 小部件应在经过训练的分类器小部件之后使用(例如朴素贝叶斯(Naive Bayes) 或者 逻辑回归(Logistics Regression))。
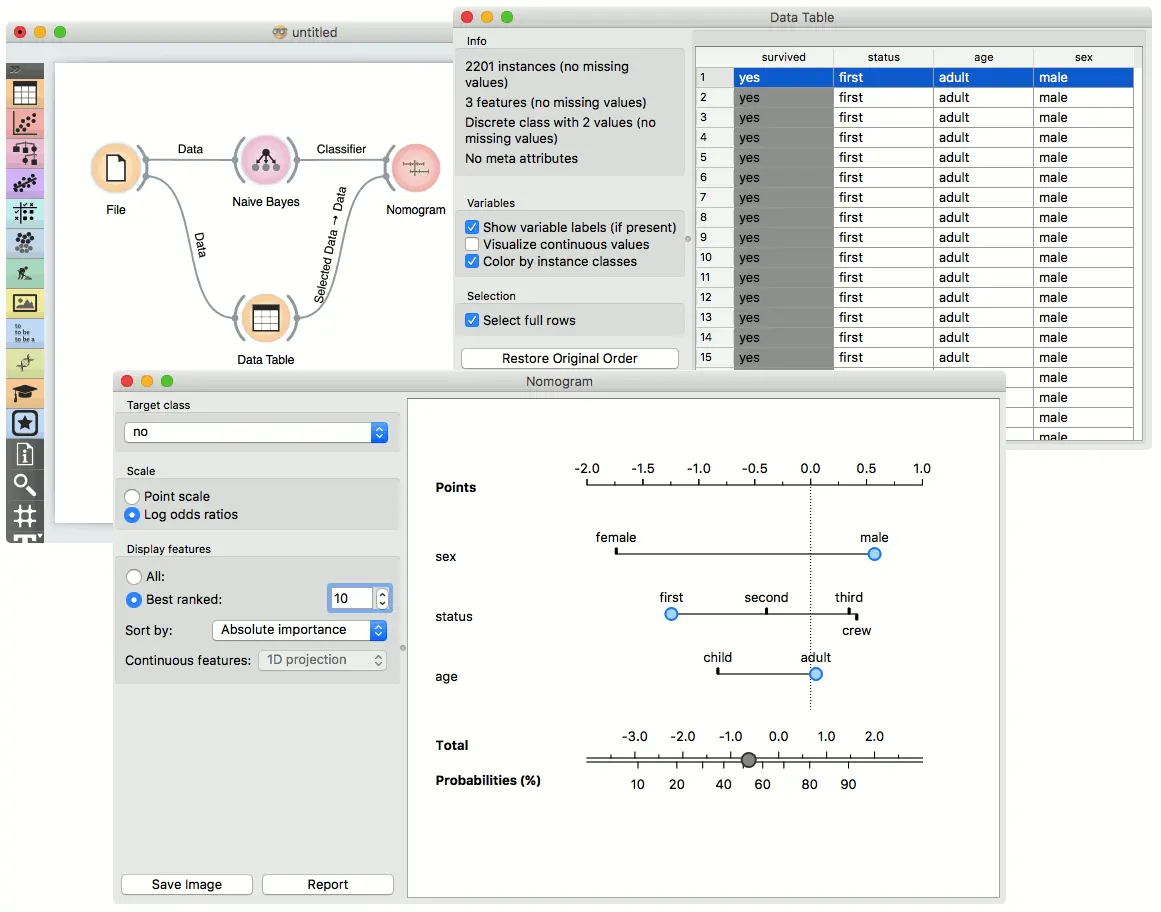
再次参考 Titanic 数据集,泰坦尼克号上2201名乘客有1490(68%)名乘客死亡。为了做出预测,将每个属性的贡献作为点得分进行测量,并对各个点得分求和以确定概率。当该属性的值未知时,其贡献为0分。 因此,对乘客一无所知,总分为0,相应的概率等于无条件先验。 示例中的列线图显示了当我们知道该乘客是头等舱的男性成年人时的情况。 这些点的总和为-0.36,相应的未幸存概率约为53%。
特征输出
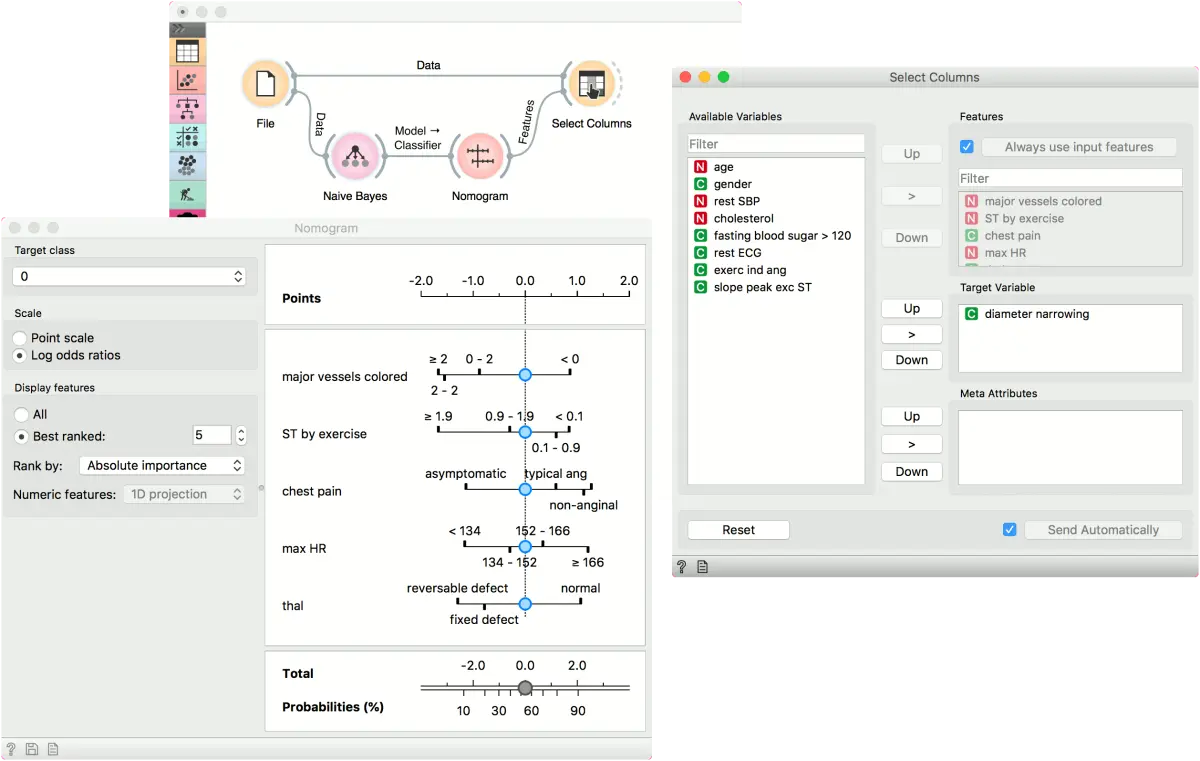
第二个示例显示如何使用特征输出。 让我们在练习中使用 heart_disease 数据并将其加载到文件(File)小部件中。 现在,将文件(File)连接到朴素贝叶斯(Naive Bayes)(或逻辑回归(Logistics Regression)),并将列线图(Nomogram) 添加到朴素贝叶斯(Naive Bayes)。 最后,将文件连接到选择列(Select Columns)。
选择列(Select Columns)选择变量的子集,而列线图(Nomogram) 显示训练过的的分类器的最高得分变量。要通过列线图(Nomogram) 中选择的变量过滤数据,请将列线图(Nomogram) 连接到选择列(Select Columns),如下所示。 列线图(Nomogram) 会将所选变量的列表传递给“选择列(Select Columns),选择列(Select Columns)将仅保留列表中的变量。 为此,您必须在选择列(Select Columns)中按 使用输入特征(或勾选以始终应用它)。
我们在列线图(Nomogram) 中选择了前5个变量,并使用 选择列(Select Columns)仅保留了这些变量。
反馈问题
文档有问题? 或者有其他意见和建议? 请在本文档的 Github 仓库直接反馈
点我反馈进入反馈页面不知道如何反馈, 请点击这里