文档嵌入(Document Embedding)
通过使用预先训练的fastText模型将文档嵌入向量空间,该模型在E. Grave等人(2018)中描述。
输入
- 语料库: 输入的文件.
输出
- 语料库: 文档集合。
Document Embedding parses n-grams of each document in corpus, obtains embedding for each n-gram using pre-trained model for chosen language and obtains one vector for each document by aggregating n-gram embeddings using one of offered aggregators. Note that method will work on any n-grams but it will give best results if corpus is preprocessed such that n-grams are words (because model was trained to embed words).
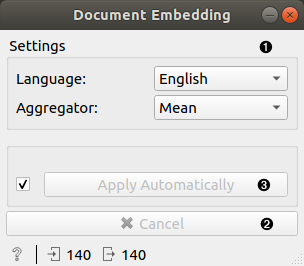
- Widget parameters:
- Language: widget will use a model trained on documents in chosen language.
- Aggregator: operation to perform on n-gram embeddings to aggregate them into a single document vector.
- Cancel current execution.
- If Apply automatically is checked, changes in parameters are sent automatically. Alternatively press Apply.
Embedding retrieval
Document Embedding takes n-grams (tokens), usually produced by the Preprocess Text widget. One can see tokens in the Corpus Viewer widget by selection Show tokens and tags or in Word Cloud. Tokens are sent to the server where each token is vectorized separately and then the aggregation function is used to compute the document embedding. The server returns the vector for each document. Currently, the server runs fasttext==0.9.1. For out-of-vocabulary (OOV) words, fastText obtain vectors by summing up vectors for its component character n-grams.
Examples
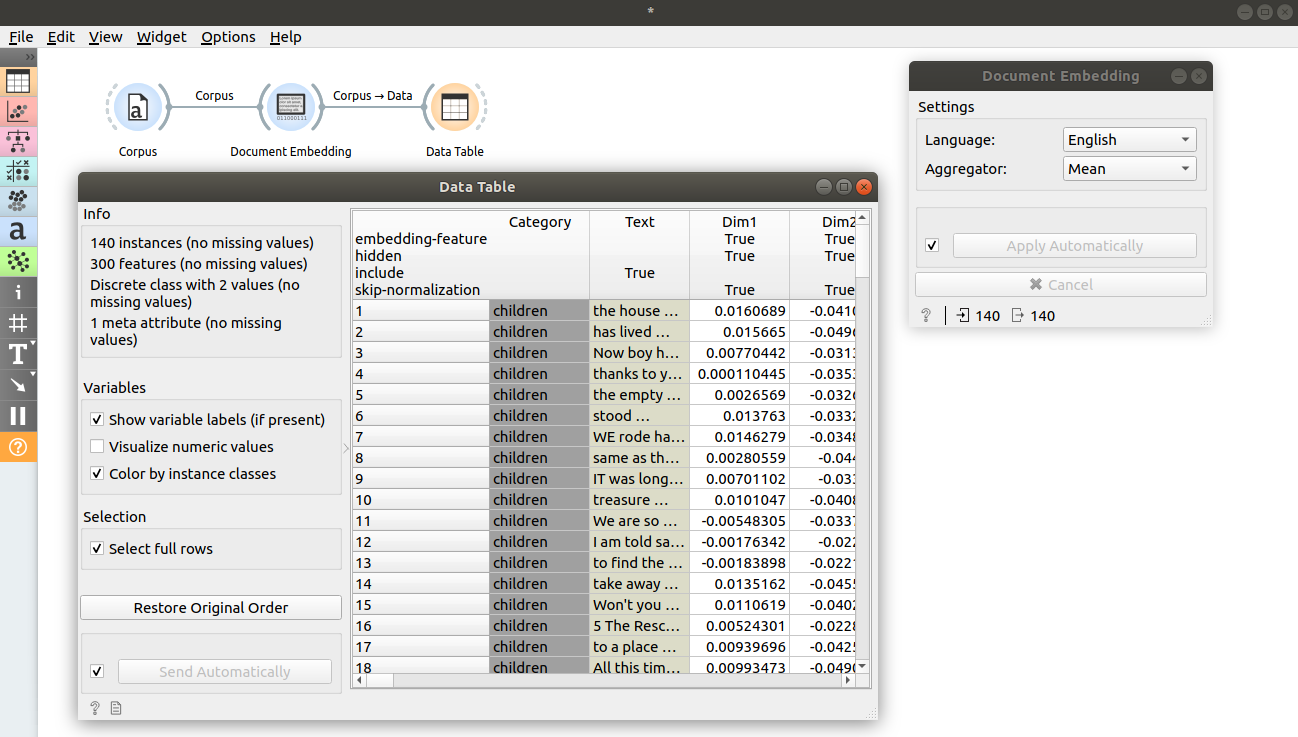
In first example, we will inspect how the widget works. Load book-excerpts.tab using Corpus widget and connect it to Document Embedding. Check the output data by connecting Document Embedding to Data Table. We see additional 300 features that we widget has appended.
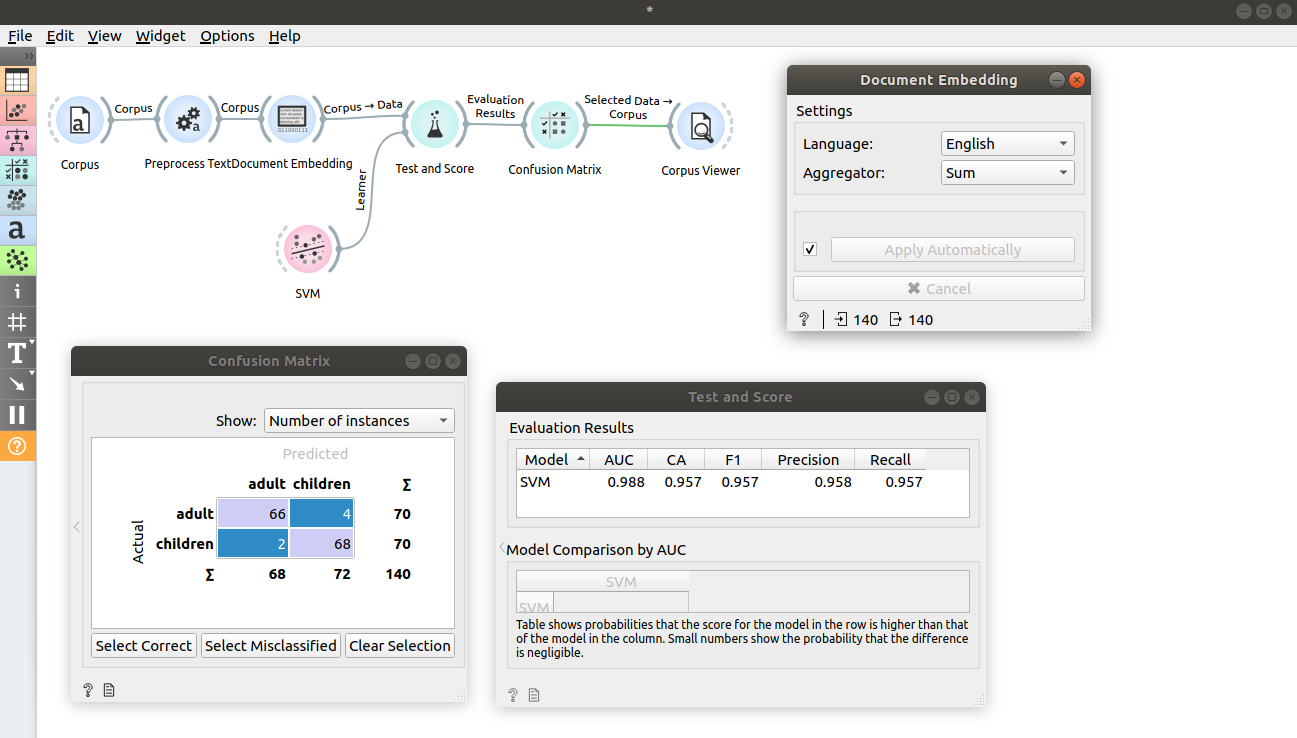
In the second example we will try to predict document category. We will keep working on book-excerpts.tab loaded with Corpus widget and sent through Preprocess Text with default parameters. Connect Preprocess Text to Document Embedding to obtain features for predictive modelling. Here we set aggregator to Sum.
Connect Document Embedding to Test and Score and also connect learner of choice to the left side of Test and Score. We chose SVM and changed kernel to Linear. Test and Score will now compute performance of each learner on the input. We can see that we achieved great results.
Let’s now inspect confusion matrix. Connect Test and Score to Confusion Matrix. Clicking on Select Misclassified will output documents that were misclassified. We can further inspect them by connecting Corpus Viewer to Confusion Matrix.
References
E. Grave, P. Bojanowski, P. Gupta, A. Joulin, T. Mikolov. “Learning Word Vectors for 157 Languages.” Proceedings of the International Conference on Language Resources and Evaluation, 2018.
反馈问题
文档有问题? 或者有其他意见和建议? 请在本文档的 Github 仓库直接反馈
点我反馈进入反馈页面不知道如何反馈, 请点击这里