人工智能概述
人工智能是什么?它从哪里来,将要到那里去?它是一门计算机科学吗?它是《星际迷航》中的“Data”,还是人类的“终结者”或者“机械公敌”?或者是《人工智能》中的机器人大卫?呃,简单来说:是也不是。
起源
我们的大脑不仅仅是看到的血肉,还有其中的“精神”。对于人工智能来说,我们不仅仅需要计算机硬件本身,还需要一种能够实现人工智能的方法。我们思考一个问题而不得其答案的时候,一般不会认为我们的脑子坏掉了,而是觉得我们没有找到一个合适的方法。同样,我们在关注人工智能的时候,更多的是关注其实现方法,而不是用的什么硬件。这里不是说硬件不重要,设想我们人类简单的思想放在其他动物头脑里的情况。没有硬件的支撑,人工智能只能是空中楼阁。
那么我们有什么实现方法呢?1936年艾伦·图灵发明了通用图灵机。这种多用途模型可以“运行”任何指令序列。图灵自己描述说:“它可以表达成一台单一的特殊机器,这种机器可以被塑造为去做所有工作。事实上,它可以被塑造成如同任何其他机器的模型般工作。这种特殊机器或许可以被称为通用机器。”
1950年,图灵发表了题为《机器能思考吗》的论文。论文的开篇是一条明确的声明:“我准备探讨‘机器能思考吗’这个问题。”童心未泯的图灵设计了一个游戏来解释这个问题的实证含义。他为人工智能给出了一个完全可操作的定义:如果一台机器输出的内容和人类大脑别无二致的话,那么我们就没有理由坚持认为这台机器不是在“思考”。这就是“人工智能”的最初设想,这份设想也在无形中让图灵摘得了“人工智能之父”的桂冠。而这个模仿测试也就是著名的“图灵测试”。
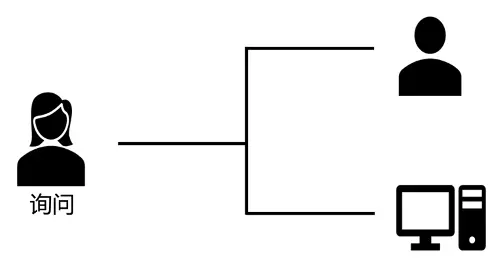
图灵测试由计算机、被测试的人和主持试验的人组成。测试过程由主持人提问,计算机和被测试的人分别做出回答。被测人在回答问题时尽可能表明他是一个“真正的”人,而计算机也将尽可能逼真的模仿人的思维方式和思维过程。
进行多次测试后,如果有超过30%的测试者不能确定出被测试者是人还是机器,那么这台机器就通过了测试,并被认为具有人类智能。
实现
沿着这条思路,接下来的问题就是如何实现?
20世纪50年代的一个大事件就是1952年阿瑟·塞缪尔教会了计算机下西洋跳棋(checker)并且还赢了自己。这件事成为了众多报纸的头条,因为计算机超过了老师,并且预示着有一天将会在各个方面超过人类。塞缪尔与这个程序对局了很多次,并观察到这个程序在经过一段时间的学习后可以发挥得更好。他提出了“机器学习”(machine learning),并将其定义为“不需要明确编程就能学习的能力”,推动了人工智能进入第一个发展高潮。

玩一玩西洋跳棋:https://cardgames.io/checkers/
另一个重大成就是逻辑理论机(Logic Theory Machine),由艾伦·纽厄尔、司马贺(赫伯特•亚历山大•西蒙)和约翰·克里夫·肖于1955年和1956年间编写的计算机程序,是首个可以模仿人类如何解决问题的程序,被称为“史上首个人工智能程序”。它证明了在怀特·黑德和罗素合作撰写的数学原理中首52个定理中的38个,而且还找到一个更优雅的证明方法。阿瑟·塞缪尔的跳棋还仅仅是一个游戏,逻辑理论机却已经是一个顶尖的逻辑学家了。
不过逻辑理论机很快就被通用求解器(General Problem Solver,GPS)超过了,这并不是说GPS的逻辑更优雅,而是GPS更通用。GPS基于逻辑理论机的原理,是由司马贺、约翰·克里夫·肖和艾伦·纽厄尔三人于1957年编写的计算机程序,旨在作为通用问题的求解器。程序员确定特定领域相关的目标和操作方法,然后将如何推理交给GPS。它可以解决“三个和尚和三个食人族怪物要过河”,汉诺塔等问题,这些问题对于人类来说也不简单。

逻辑理论机和GPS是GOFAI的早期例子(Good Old-Fashioned Artificial Intelligence),意思是“好的老式人工智能” 。它们现在是“老式的”,但他们也很“好”,因为它们率先使用启发式和规划算法 - 这两者在今天的人工智能中都非常重要。
1957年,罗森·布拉特基于神经感知科学背景提出了第二模型,非常的类似于今天的机器学习模型。这在当时是一个非常令人兴奋的发现。基于这个模型他设计出了第一个计算机神经网络——感知机(perceptron),它模拟了人脑的运作方式。在软件实现感知机之后,他于1960年开始构建硬件版本的感知机:Mark I,它用400个光电设备组成神经元。 突触权重由电位计编码,并且学习期间的权重变化由电动机执行。由于当时的技术限制,这类物理实现的感知机还是很罕见的。并且,由于人工智能另一个分支, 符号主义的发展,这部分研究趋于停滞。

1960年维德罗和霍夫提出了自适应线性单元,一种连续取值的人工神经网络,可用于自适应系统。随即人工神经网络进入第一个研究高潮期(这种方法后来被称为最小二乘方法)。
一个非常著名的机器学习算法决策树算法(ID3)由罗斯·昆兰在1986年提出。此外,与黑盒神经网络模型截然不同的是,决策树ID3算法通过使用简单的规则和清晰的参考可以找到更多的现实生活中的使用情况。
沉寂10年之后,神经网络也有了新的研究进展,尤其是1982年英国科学家霍普菲尔德几乎同时与杰弗里·辛顿发现了具有学习能力的神经网络算法,这使得神经网络一路发展,在后面的90年代开始商业化,被用于文字图像识别和语音识别。

1990年, Schapire构造出最初的 Boosting算法。一年后 Freund提出了一种效率更高的Boosting算法。但是,这两种算法存在共同的实践上的缺陷 ,那就是都要求事先知道弱学习算法学习正确的下限。
1995年 , Freund和Schapire改进了Boosting算法,提出了 AdaBoost (Adaptive Boosting)算法,该算法效率和 Freund于 1991年提出的 Boosting算法几乎相同 ,但不需要任何关于弱学习器的先验知识,因而更容易应用到实际问题当中。
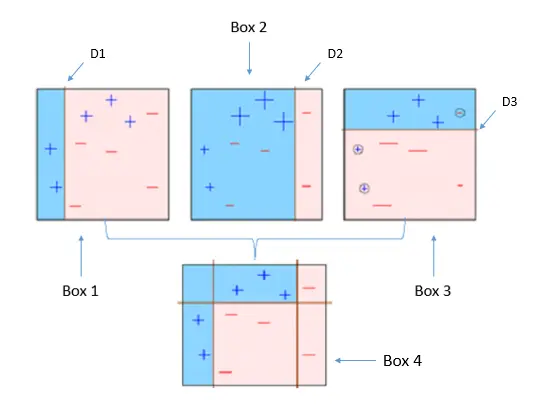
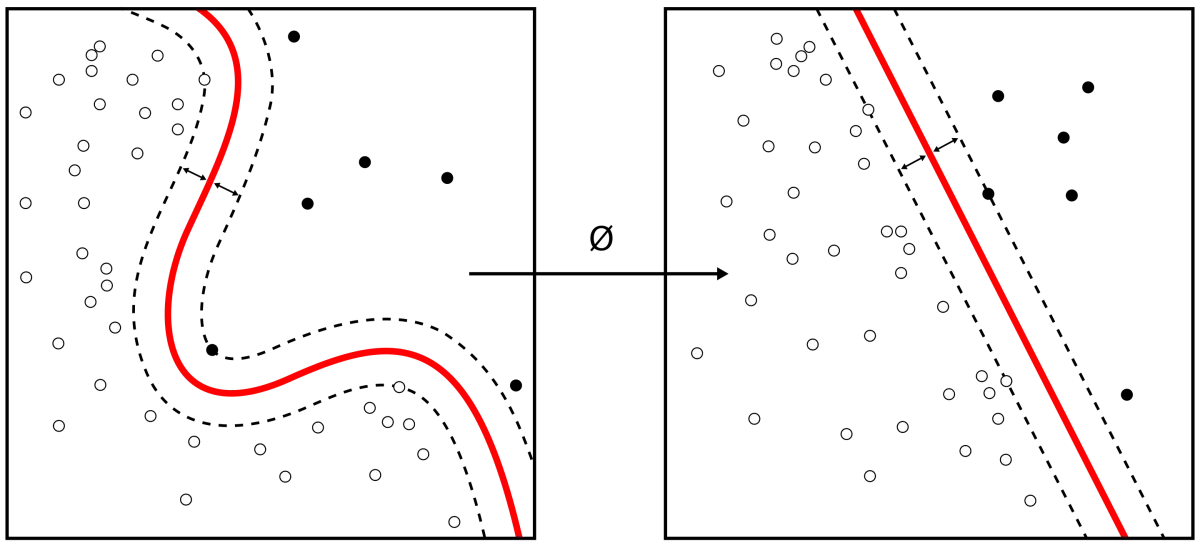
同年,机器学习领域中一个重要的突破,支持向量机(support vector machines, SVM ),由瓦普尼克和科尔特斯在大量理论和实证的条件下提出。从此将机器学习社区分大致为神经网络社区和支持向量机社区。
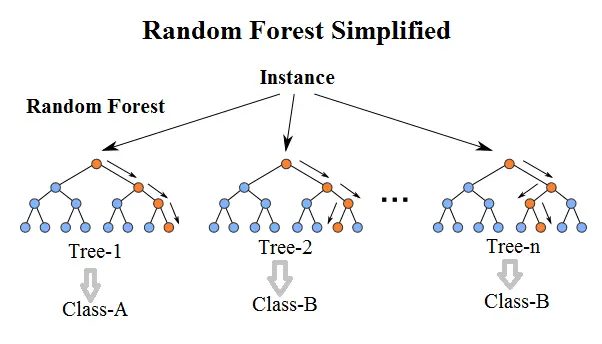
另一个集成决策树模型由布雷曼博士在2001年提出,它是由一个随机子集的实例组成,并且每个节点都是从一系列随机子集中选择。由于它的这个性质,被称为随机森林,随机森林也在理论和经验上证明了对过拟合的抵抗性。
1997年,两位德国科学霍克赖特和施米德赫伯提出了长期短期记忆(LSTM), 这是一种今天仍用于手写识别和语音识别的递归神经网络,对后来人工智能的研究有着深远影响。2006年,杰弗里辛顿出版了《Learning Multiple Layers of Representation》奠定了后来神经网络的全新的架构,至今仍然是人工智能深度学习的核心技术。
2007年,在斯坦福任教的华裔科学家李飞飞,发起创建了ImageNet项目。
2012 年,辛顿课题组为了证明深度学习的潜力,首次参加ImageNet图像识别比赛,其通过构建卷积神经网络AlexNet一举夺得冠军,且碾压第二名(SVM方法)的分类性能。也正是由于该比赛,卷积神经网络(CNN)吸引到了众多研究者的注意。
2014年,伊恩·古德费罗提出生成对抗网络(Generative Adversarial Net,GAN),这是一种用于无监督学习的人工智能算法,这种算法由生成网络和评估网络构成,以左右互搏的方式提升最终效果,这种方法很快被人工智能很多技术领域采用。
2016年,李世石与AlphaGo总比分1比4告负,将公众的视注意力也大量投向了人工智能,真正地将人工智能推向了研究和公众视野的中心。

反馈问题
文档有问题? 或者有其他意见和建议? 请在本文档的 Github 仓库直接反馈
点我反馈进入反馈页面不知道如何反馈, 请点击这里