语料查看器(Corpus Viewer)
显示语料库内容。
输入
- 语料库: 文件集。
输出
- 语料库: 含有查询词的文件。
功能
语料查看器是用来查看文本文件(语料库实例)的。它总是会输出一个语料库的实例。如果使用 正则表达式 过滤,小组件将只输出匹配的文件。
界面
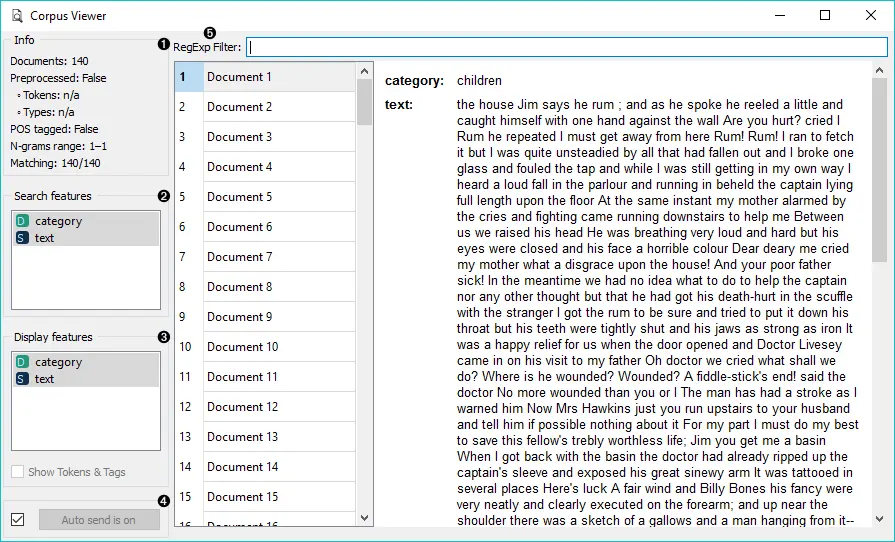
- 信息:
文件:输入的文件数量。预处理:如果使用了预处理程序,结果为True,否则为False。同时报告词的数量和类型(唯一词)。POS标签:如果输入上有POS标签,结果为True,否则为False。N-grams范围:如果在文本预处理中设置了N-grams,则报告结果,默认为1-1(1-gram)。匹配:与正则表达式删选匹配的文档数量。默认情况下,所有文档都会输出。
- 正则表达式筛选。使用Python正则表达式过滤文档。默认情况下,不过滤任何文档(输出的是整个语料库)。
- 搜索特征:正则表达式筛选的特征。使用Ctrl(Cmd)选择多个特征。
- 显示特征:在查看器中显示的特征。使用Ctrl(Cmd)选择多个特征。
- 显示词和标签:如果输入上有词和POS标签,可以勾选此框来显示它们。
- 如果自动提交开启,则会自动传达更改。或者按提交。
示例
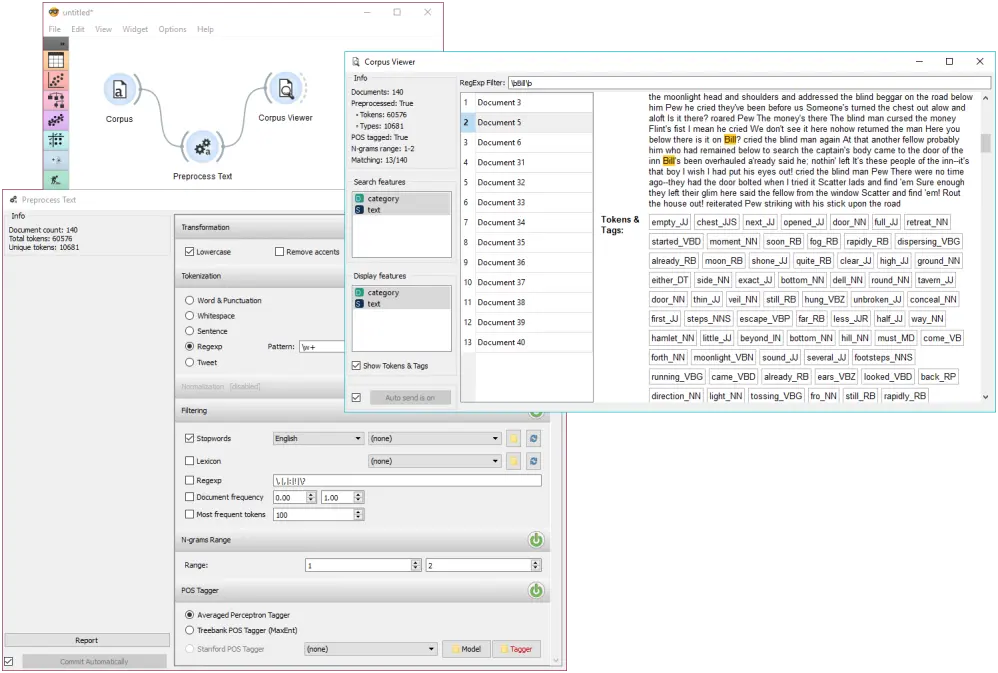
语料查看器(Corpus Viewer)可以用来显示语料库中的全部或部分文档。在这个例子中,我们将首先把此插件中已经附带的 book-excerpts.tab 加载到[预料库]小部件中。然后我们将对文本进行预处理,将其转化为单词,过滤掉停用词,创建2-grams,并添加 POS 标签(更多关于预处理的内容请参见 文本预处理。现在我们要查看预处理的结果。在语料查看器(Corpus Viewer)中,我们可以看到,我们得到了多少唯一的标记,以及它们是什么(勾选显示词和标签)。由于我们还使用了POS标签来显示部分part-of-speech标签,它们将与文本下方的标记一起显示。
现在我们将只过滤掉谈论 Bill 这个字符的文档。我们使用正则表达式 \bBill\b 来查找只包含Bill这个词的文档。你可以输出匹配或不匹配的文档,在另一个语料查看器(Corpus Viewer)中查看它们或进一步分析它们。
反馈问题
文档有问题? 或者有其他意见和建议? 请在本文档的 Github 仓库直接反馈
点我反馈进入反馈页面不知道如何反馈, 请点击这里