混淆矩阵(Confusion Matrix)
显示预测类和实际类之间的比例。
输入
- 评估结果:测试分类算法的结果
输出
- 选定的数据:从混淆矩阵中选择的数据子集
- 数据:具有有关是否选择数据实例的附加信息的数据
功能
混淆矩阵给出了预测类和实际类之间的实例数量或比例。矩阵中元素的选择将相应的实例输入到输出信号中。这样,就可以观察到哪些特定实例被错误分类以及如何分类。
该小部件通常从测试与评分(Test & Score)获取评估结果; 模式的示例如下所示。
界面
-
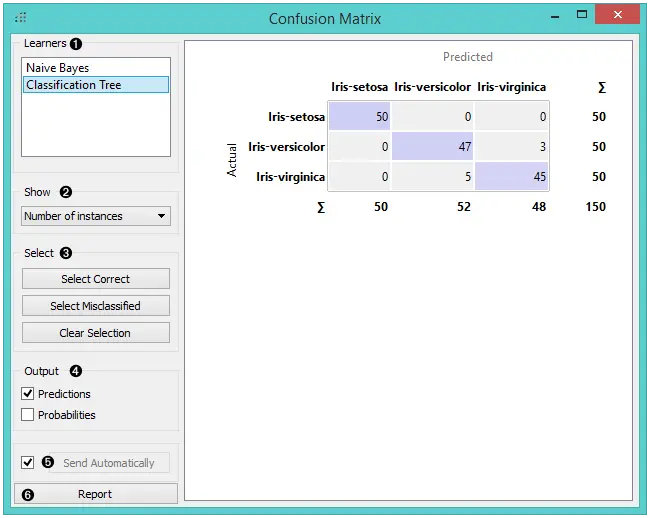
当评估结果包含有关多种学习算法的数据时,我们必须在 学习器 框中选择一个。
截图显示了在 iris 数据上经过训练和测试的树(Tree) 和朴素贝叶斯(Naive Bayesian)模型的混淆矩阵。小部件的右侧包含朴素贝叶斯模型的矩阵(因为在左侧选择了该模型)。每行对应一个正确的类别,而列则代表预测的类别。 例如,Iris-versicolor 的四个实例被错误地分类为 Iris-virginica。最右边的一列给出了每个类别的实例数(三个类别中的每个有 50 个 irises),最下面的行给出了分类为每个类别的实例数(例如,将 48 个实例分类为 virginica)。
- 在 显示 中,我们选择要在矩阵中看到的数据。
- 实例数量 以数值显示正确和错误分类的实例。
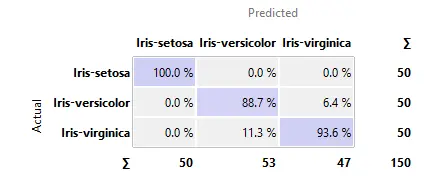
- 预测比例
- 实际比例
- 在 选择 中,您可以选择所需的输出。
- 选择正确分类 通过选择矩阵的对角线将所有正确分类的实例发送到输出。
- 选择错误分类 选择错误分类的实例。
- 清除选定内容 取消选择。 如前所述,您还可以选择表格中的各个单元格,以选择特定种类的误分类实例。
- 发送选定的实例时,如果选中了相应的选项
预测和/或概率,则窗口小部件可以添加新属性,例如预测类或它们的概率。 - 如果勾选了 自动应用,小部件将输出所有更改。 否则,用户将需要单击 应用 来提交更改。
- 生成报告。
示例
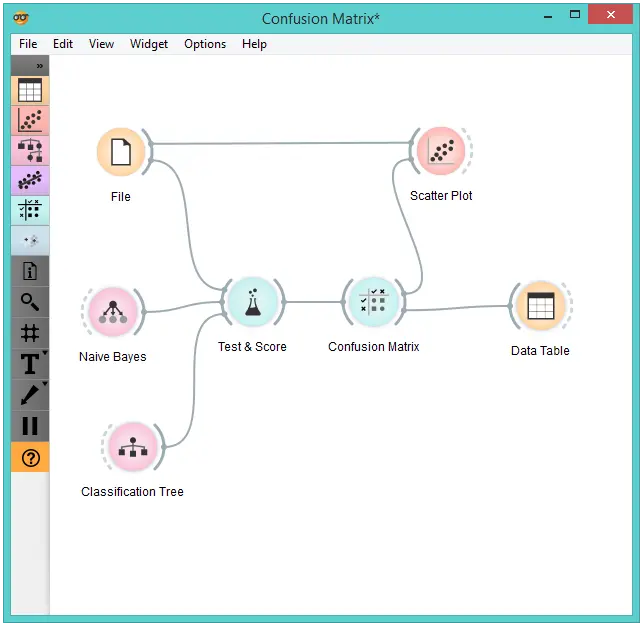
测试与评分(Test & Score)从文件(File) 获取数据,并从朴素贝叶斯(Naive Bayes) 树(Tree)获得两种学习算法。 它执行交叉验证或其他训练和测试过程,以通过两种算法针对所有(或某些)数据实例获得类别预测。测试结果被输入到 混淆矩阵(Confusion Matrix) 中,在这里我们可以观察到有多少个实例被错误分类以及以哪种方式分类。
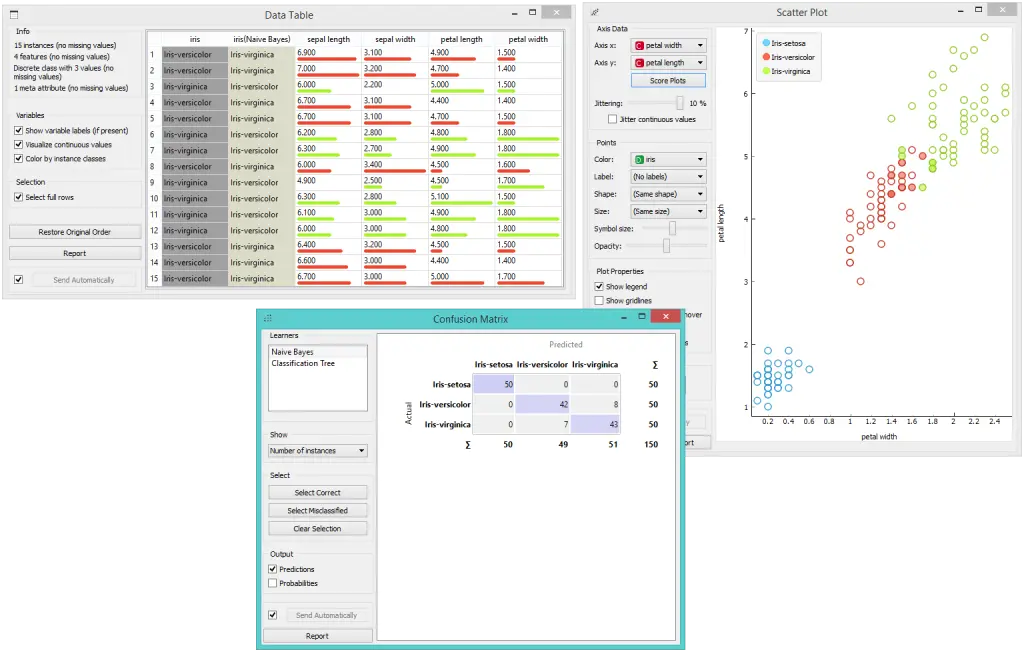
在输出中,我们使用数据表(Data Table)展示了我们在混淆矩阵中选择的实例。 例如,如果我们单击 错误分类,该表将包含被所选方法分类错误的所有实例。
散点图(Scatter Plot)获取两组数据。 从 文件(File)小部件获取完整数据,而混淆矩阵仅发送所选数据,例如错误分类。散点图(Scatter Plot) 将显示所有数据,其中粗体符号代表所选数据。
反馈问题
文档有问题? 或者有其他意见和建议? 请在本文档的 Github 仓库直接反馈
点我反馈进入反馈页面不知道如何反馈, 请点击这里