填充(Impute)
替换数据中的未知值。
输入
- 数据: 输入数据集
- 学习器: 填充学习算法
输出
- 数据: 填充后的数据集
功能
某些橙现智能的算法和可视化效果不能处理数据中的缺失值。此小部件执行统计人员所说的填充:它通过根据数据计算或用户设置的值替换缺失值。默认填充为(1-NN)。
界面
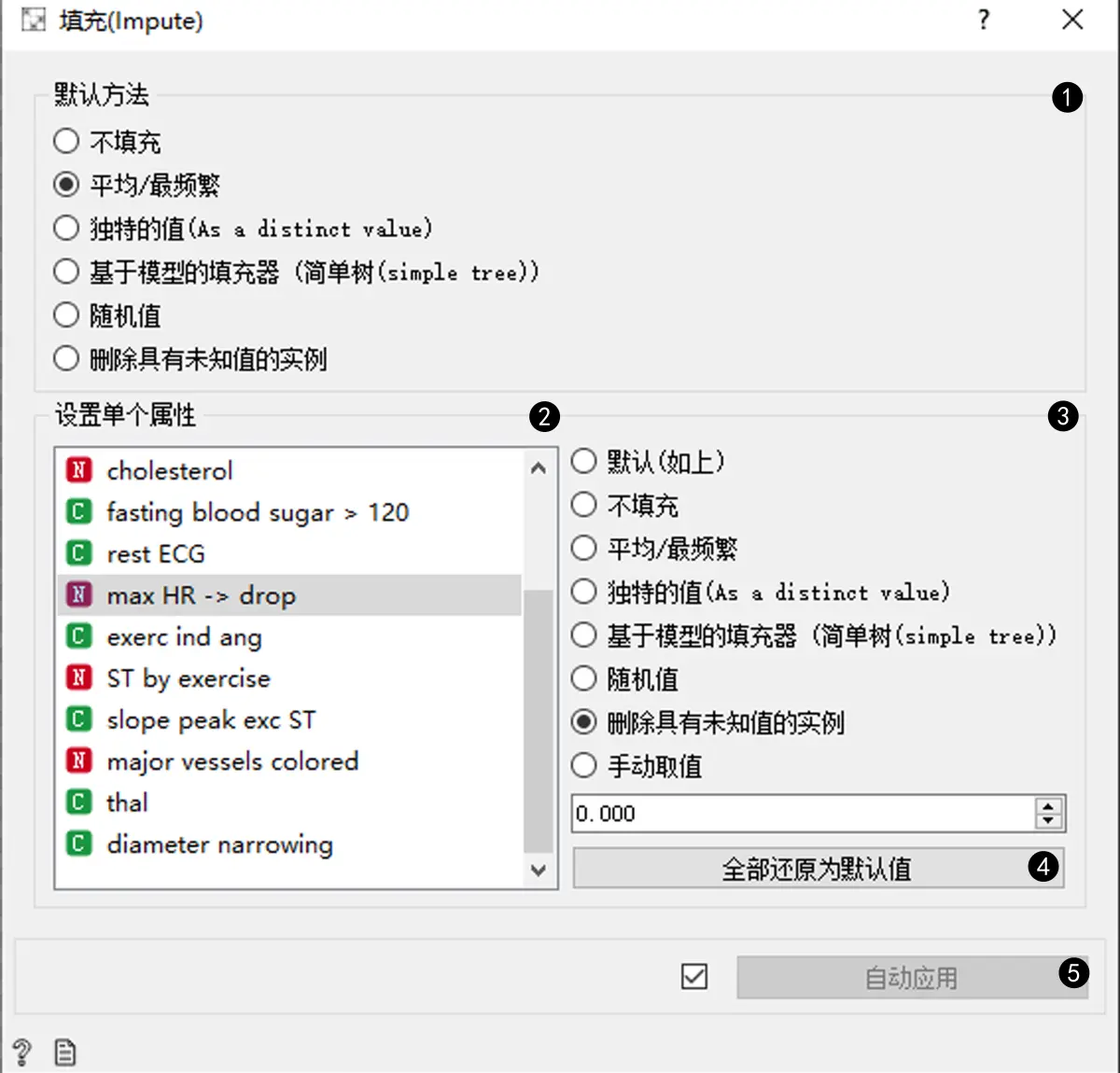
- 选择一个默认方法,为所有特征指定一个通用填充方法。
- 不填充 将不会对缺失的值做任何处理。
- 平均/最频繁:对于连续属性使用平均值,对于离散属性使用最频繁值。
- 独特的值:创建新的值以替换缺少的值。
- 基于模型的填充值:根据其他特征的值构造一个预测缺失值的模型;为每个属性构建一个单独的模型。默认模型是1-NN 学习器,它会从最相似的样本中获取值(这有时被称为hot-deck填充)。该算法可由用户连接到输入端的学习器进行填充。但是,如果数据中存在离散和连续属性,则算法需要能够同时处理这两个特征;目前只有1-NN 学习器可以做到这一点。
- 随机值:计算每个特征的值的分布,然后从中随机选取值进行填充。
- 删除具有未知值的实例:删除包含缺失值的实例。如果勾选了“填充类别”,则此检查也适用于类属性。
- 可以为每个特征指定单独的处理方式,这将覆盖默认的处理器。还可以手动定义填充值。在截图中,我们选择删除“Max HR”有缺失的值,所有其他属性的值使用上面设置的默认方法。
- 调整个别属性的填充方法。
- 此按钮会将单个属性处理重置为默认值。
- 如果勾选了 ”自动发送“,则小部件会自动将更改传达给其他小部件。
示例
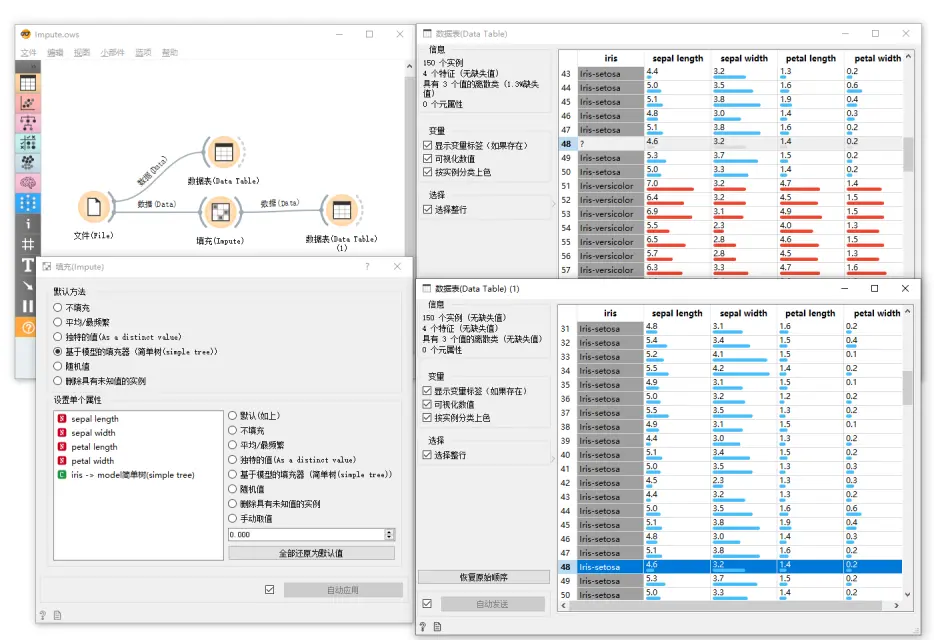
在这个示例中,我们使用 iris 数据集进行操作并删除了一些数据。我们使用 填充(Impute) 小部件,并选择了 基于模型的填充值 来计算缺失的值。在另一个数据表(Data Table)中,我们看到问号是如何变成不同值的(“Iris-setosa, “Iris-versicolor”)。
反馈问题
文档有问题? 或者有其他意见和建议? 请在本文档的 Github 仓库直接反馈
点我反馈进入反馈页面不知道如何反馈, 请点击这里