支持向量机(SVM)
支持向量机将输入映射到高维特征空间。
输入
- 数据:输入数据集
- 预处理器:预处理方法
输出
- 学习器:SVM 学习算法
- 模型:训练过的模型
- 支持向量: 用作支持向量的数据点
功能
支持向量机(SVM)是一种机器学习技术,它用超平面分隔特征空间,从而最大程度地提高了不同分类之间的边界。该技术通常会产生极高的预测性能。橙现智能从LIBSVM包中嵌入了 SVM 的流行实现。该小部件是其图形用户界面。
对于回归任务,SVM 使用 ε 不敏感损失在高维特征空间中执行线性回归。其估计精度取决于C,ε和核参数的良好设置。 窗口小部件基于SVM回归输出类别预测。
该小部件可用于分类和回归任务。
界面
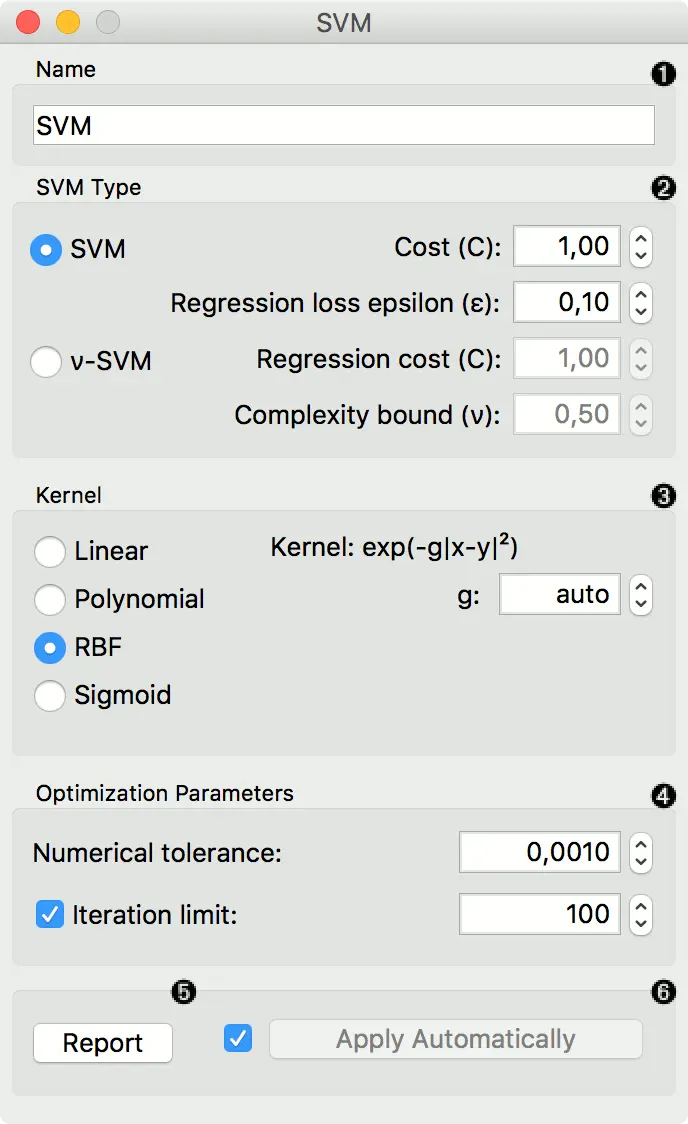
- 给学习器一个名称,该名称将出现在其他小部件中。默认名称是“支持向量机(SVM)”。
- 具有测试错误设置的SVM。 SVM和 ν-SVM 基于误差函数的不同最小化。您可以设置测试错误方法:
- 核是一种将特征空间转换为新的特征空间以适合最大边距超平面的函数,从而允许算法使用线性创建模型,多项式,RBF和Sigmoid核。选择核时会显示指定核函数,其中涉及的常量为:
g表示核函数中的gamma常数(建议值为 1/k,其中 k 为特征的数量,但是由于可能没有给小部件提供训练集,因此默认值为0,并且用户必须手动设置此选项),c表示核函数中的常数c0(默认为0),并且d表示核的等级(默认为3)。
-
在 “数值公差” 中设置与期望值的允许偏差。选中 迭代极限 旁边的框,以设置允许的最大迭代次数。
- 发送报告
- 勾选 “自动应用” 以自动传送对其他小部件的更改,并在连接学习数据后立即训练分类器。 或者,在配置后按 “应用”。
示例
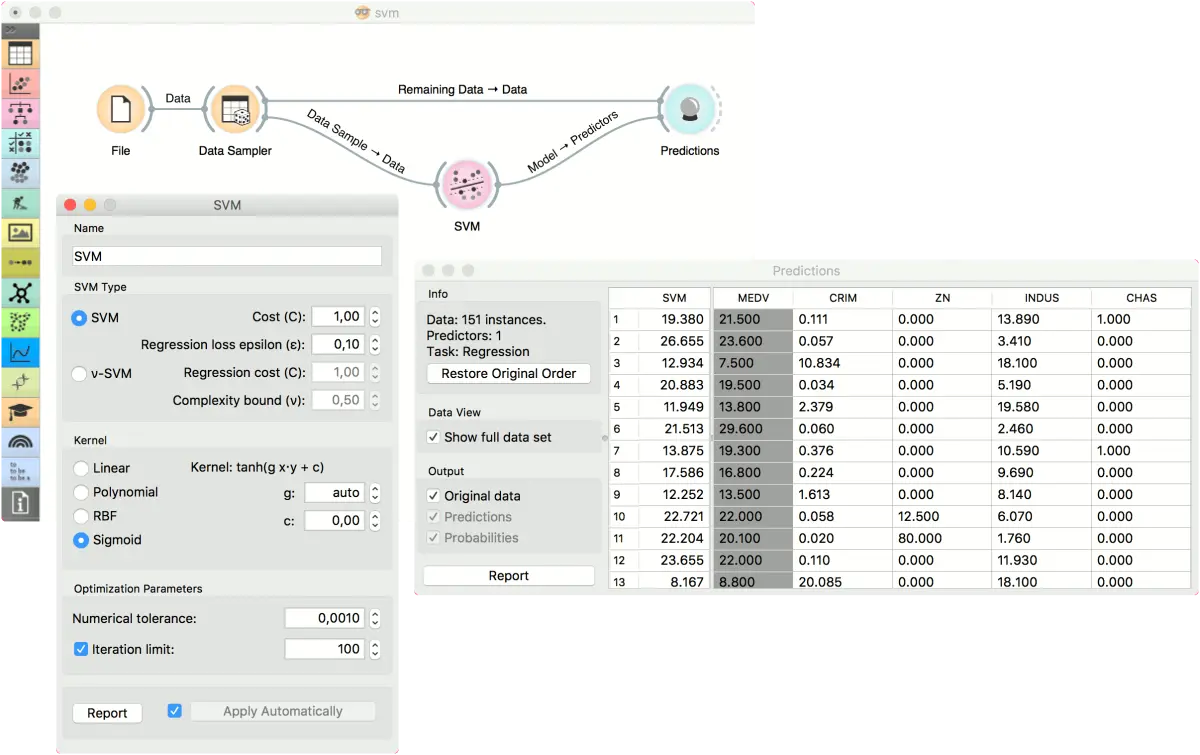
在第一个(回归)示例中,我们使用了 housing 数据集,并使用 数据采样器(Data Sampler) 将数据分为两个数据子集: 数据样本 和 剩余数据。 样本被发送到 SVM 生成一个 模型,然后将其用于预测(Predictions)中以预测 剩余数据 中的值。如果数据已经在两个单独的文件中,则可以使用类似的架构。 在这种情况下,将使用两个文件(File)小部件代替文件(File)- 数据采样器(Data Sampler) 组合。
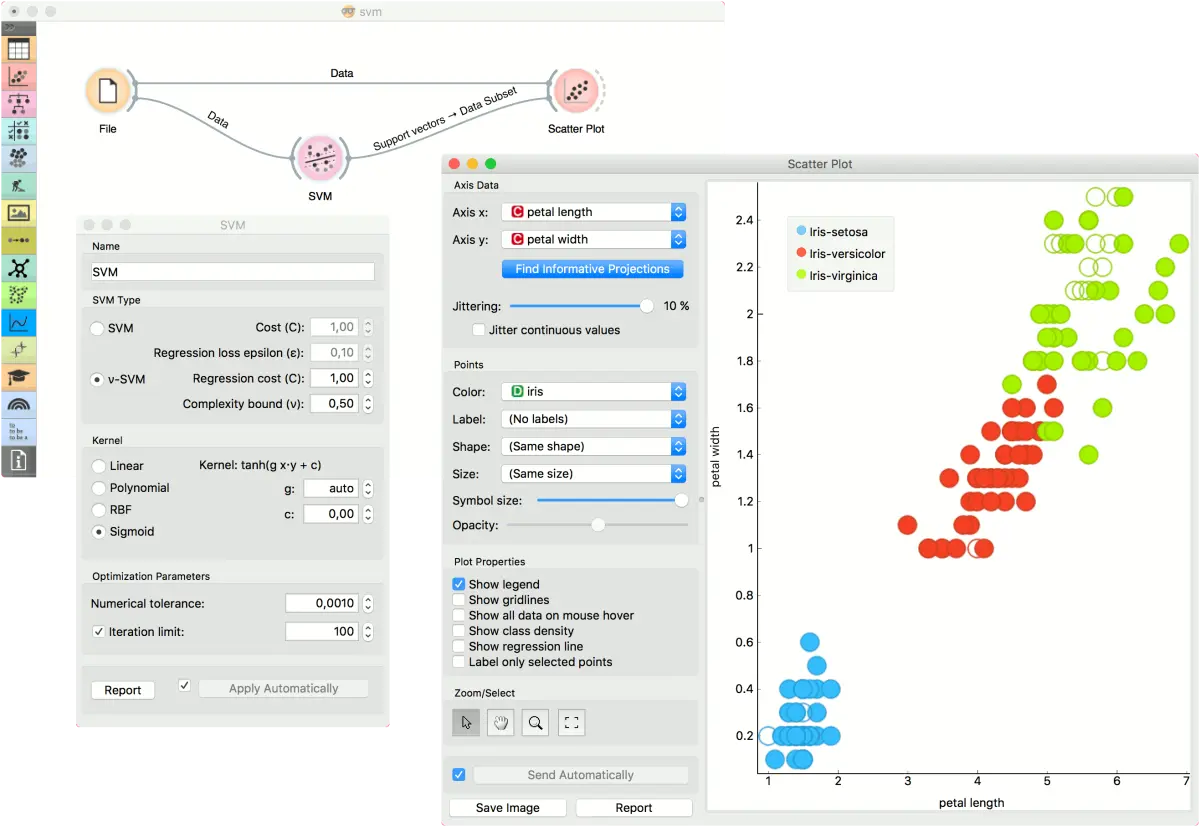
第二个示例显示了如何结合散点图(Scatter Plot)使用 支持向量机(SVM)。以下工作流程在 iris 数据上训练 SVM 模型并输出支持向量,这些向量是在学习阶段用作支持向量的那些数据实例。我们可以在散点图(Scatter Plot)可视化中观察是哪些数据实例。请注意,为使工作流正常工作,必须设置小部件之间的链接,如下面的截图所示。
参考文献
Introduction to SVM on StatSoft.
反馈问题
文档有问题? 或者有其他意见和建议? 请在本文档的 Github 仓库直接反馈
点我反馈进入反馈页面不知道如何反馈, 请点击这里