词袋(Bag of Words)
从输入的语料库中生成一个词袋。
输入
- 语料库: 文件集。
输出
- 语料库: 附加了词袋特征的语料库。
功能
词袋模型为每个数据实例(文档)创建了一个带有各个词数量的语料库。词数可以是绝对数、二进制数(包含或不包含)或次线性数(词频的对数)。词袋模型与词充实结合使用,可用于预测性建模。
界面
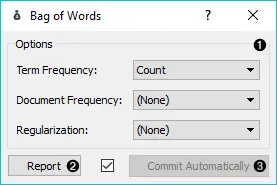
- 词袋模型的参数。
- 制作一份报告。
- 如果自动发送开启,则会自动传达更改。或者按 发送。
示例
在第一个例子中,我们将简单地检查词袋模型的大概。用语料库小部件加载book-excerpts.tab,并将其连接到词袋。这里我们保留了默认值 – 一个简单的词频计数。检查词袋在数据表输出的内容。最后一列白色的是代表每个文档的词频。
在第二个例子中,我们将尝试预测文档类别。我们仍然使用 book-excerpts.tab 数据集,我们通过文本预处理发送默认参数。然后我们将文本预处理连接到词袋,获得词频,我们将通过这个频率来计算模型。
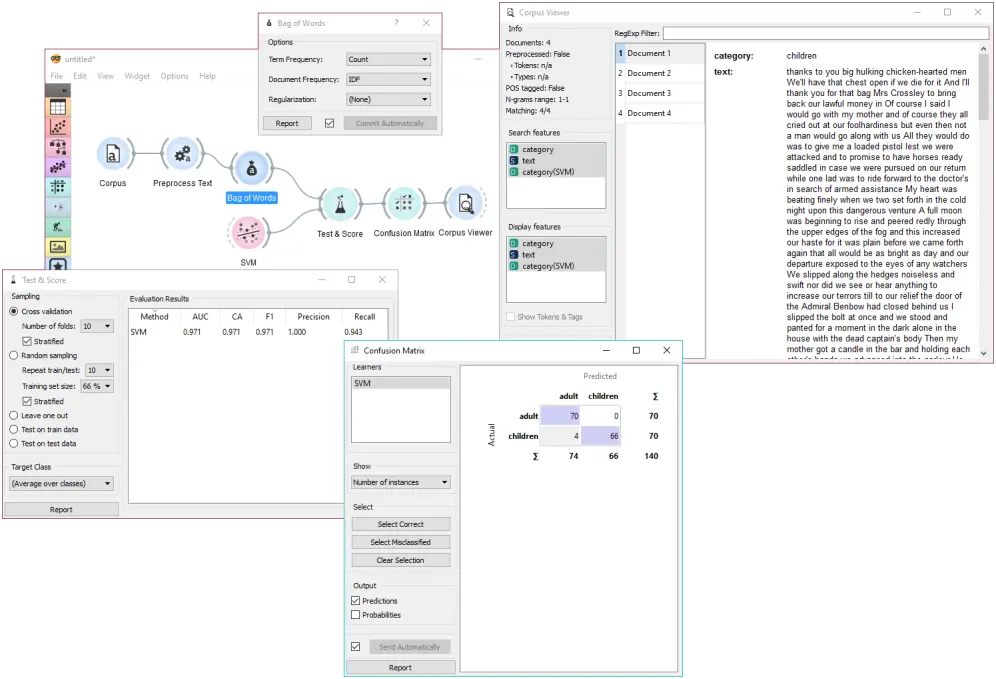
将词袋连接到测试与评分进行预测建模。将支持向量机 (SVM)或任何其他分类器也连接到测试与评分(都在左侧)。现在,测试与评分将为每个学习器计算输入的性能分数。在这里,我们用 SVM 得到了相当令人印象深刻的结果。现在我们可以检查,模型在哪里犯了错误。
在测试与评分中添加混淆矩阵。混淆矩阵显示正确和错误的分类文档。选择错误分类会输出错误分类的文档,我们可以用语料查看器进一步检查。
反馈问题
文档有问题? 或者有其他意见和建议? 请在本文档的 Github 仓库直接反馈
点我反馈进入反馈页面不知道如何反馈, 请点击这里