
使用轮廓系数吧
轮廓系数 (使用轮廓图) 显示簇内样本与最近簇内样本之间的平均距离。
对于给定的数据,接近 1 的轮廓系数表示数据样本靠近簇中心。轮廓系数接近 0 的样本位于两个簇之间的边界上。总体而言,可以通过数据样本的平均轮廓系数来评估聚类的质量。但是在这里,我们对各个轮廓及其在轮廓图中的可视化更加感兴趣。
小实验
仍然使用 iris 数据集, 我们将会计算每个数据点的轮廓系数.
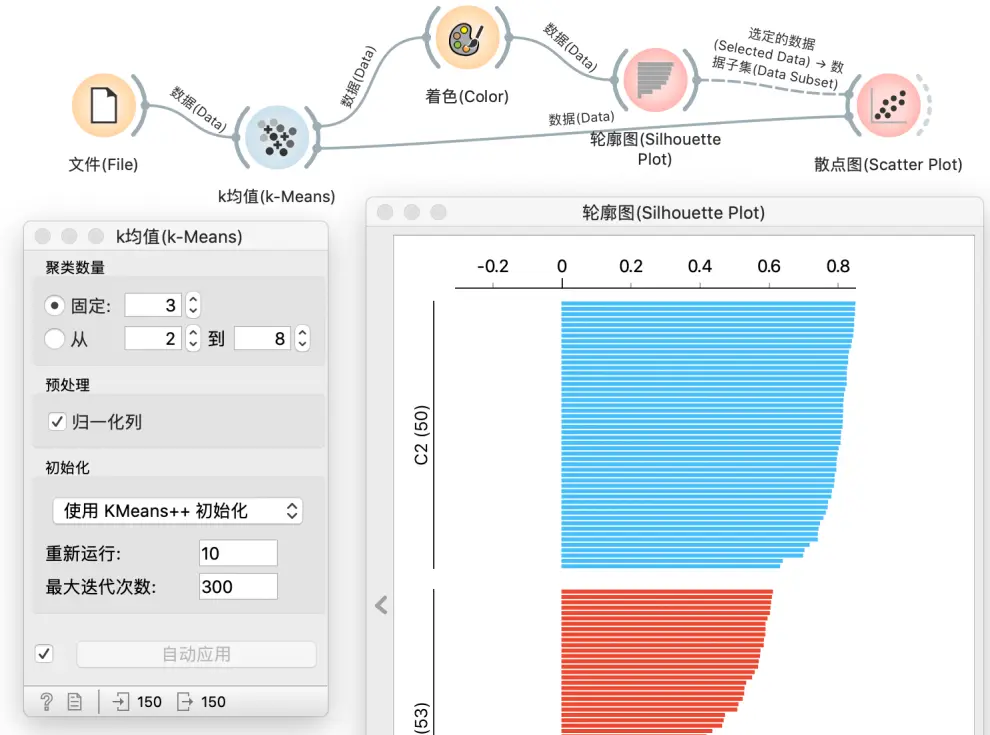
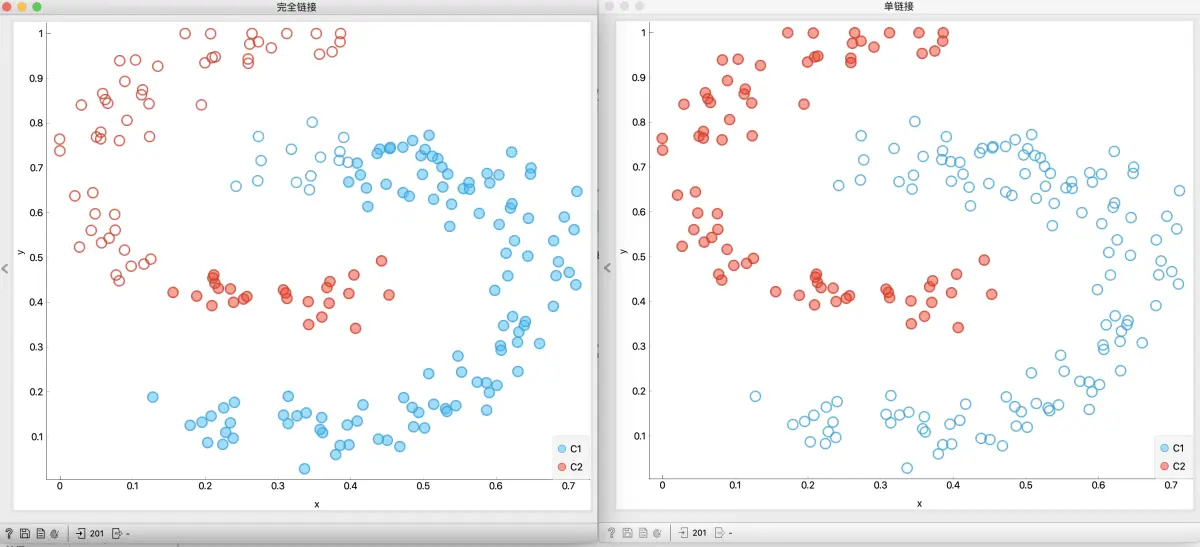
在k均值中设置聚类数量为 3, 然后用轮廓图显示. 好的簇的数据的轮廓系数大, 不过这里我们做点不一样的, 我们特意选择那些轮廓系数小的点, 看看他们有什么特点?
我们可以发现, 他们都位于两个簇的交界, 从散点图可以很清楚的看到看出来
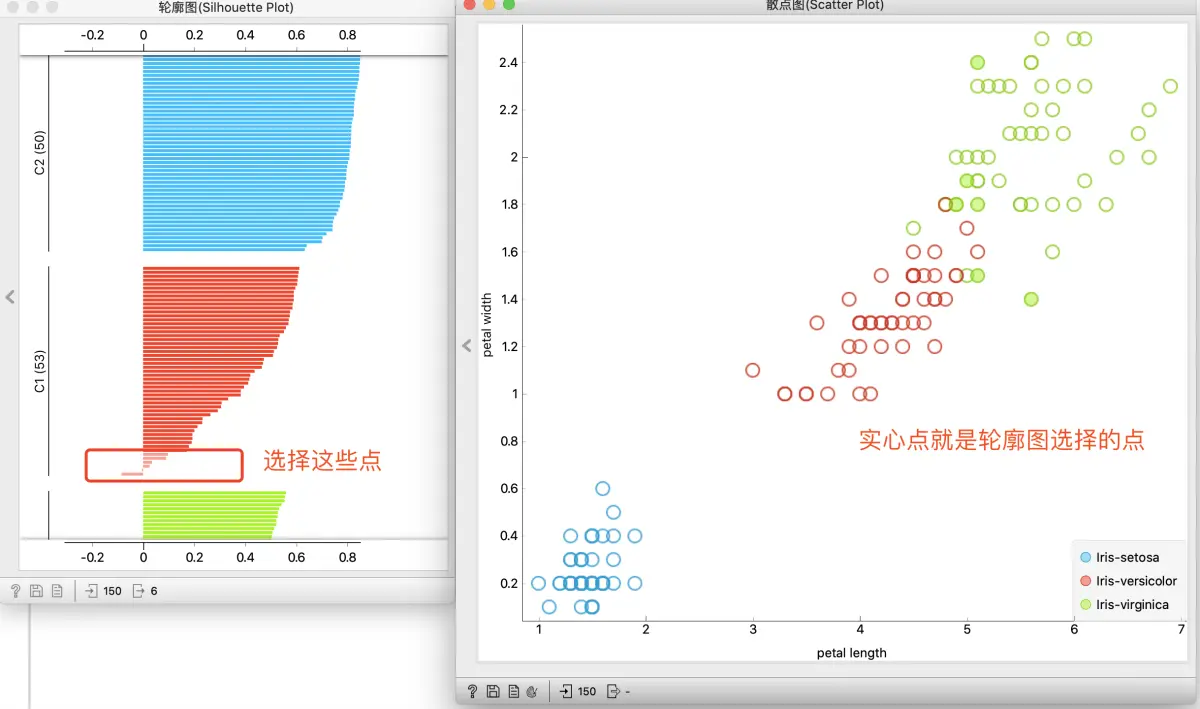
进一步分析
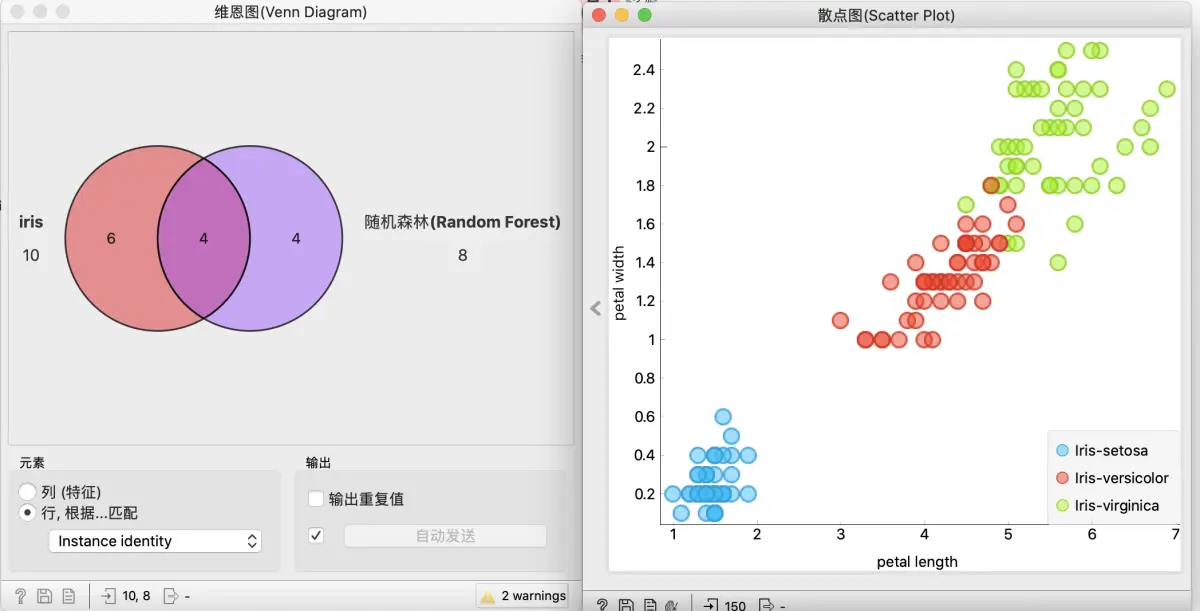
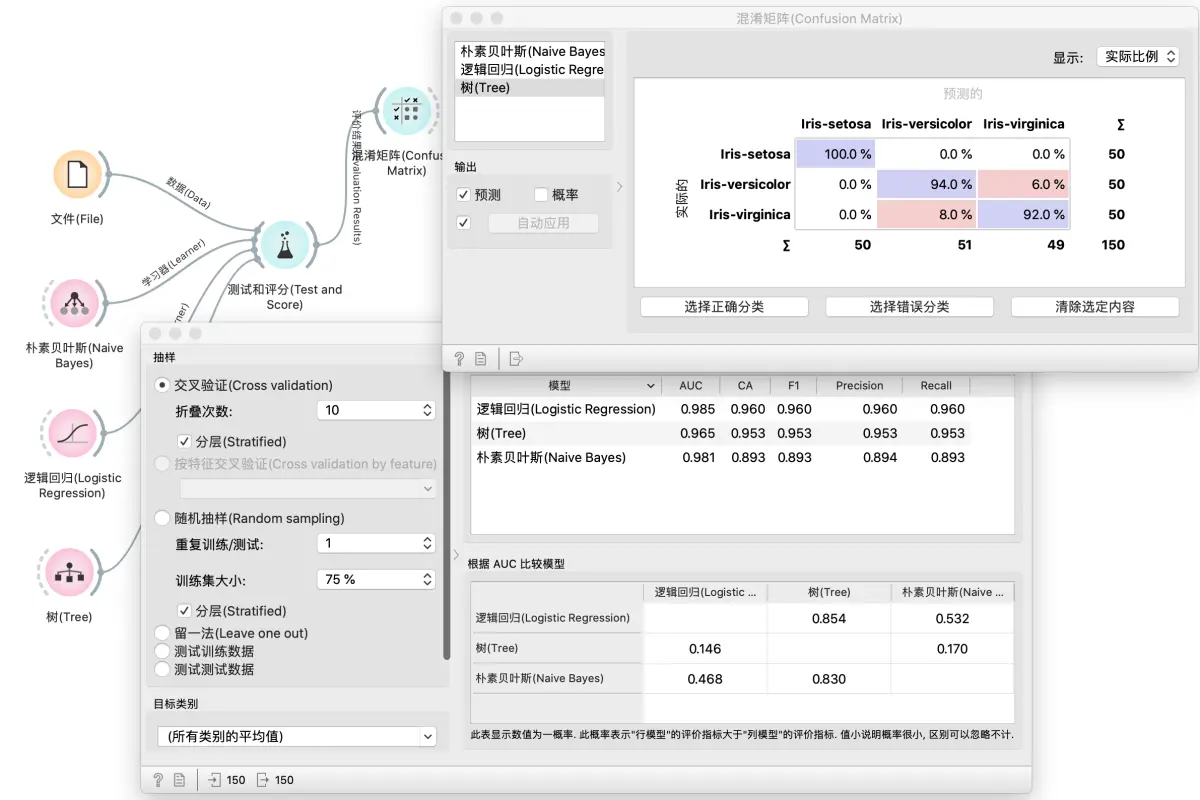
让我们再做些更有意思的事情。我们将在 iris 的类别属性上计算轮廓系数(此处不进行聚类,仅使用数据集中的原始类值)。我们的假设是:具有低轮廓值的数据也将被某些学习算法(比如随机森林)误分类,。
我们将在测试与评分中使用10次折叠交叉验证,将评估结果发送到混淆矩阵,然后选择分类错误的数据。接下来,我们在维恩图中探索低轮廓系数值的数据。两种技术之间的交集比例很高。
轮廓图是另一种出色的可视化方法,可以帮助你进行数据分析或理解某些机器学习概念。
反馈问题
文档有问题? 或者有其他意见和建议? 请在本文档的 Github 仓库直接反馈
点我反馈进入反馈页面不知道如何反馈, 请点击这里
留下评论