数据采集器(Data Sampler)
从输入数据集中选择数据实例的子集。
输入
- 数据:输入数据集
输出
- 数据样本:采样的数据实例
- 剩余的数据:样本外数据
功能
数据采样器(Data Sampler) 小部件实现了几种数据采样方法。 它输出一个采样数据集和未被采样的数据集。提供了输入数据集并点击 执行抽样 按钮后,就会输出数据。
界面
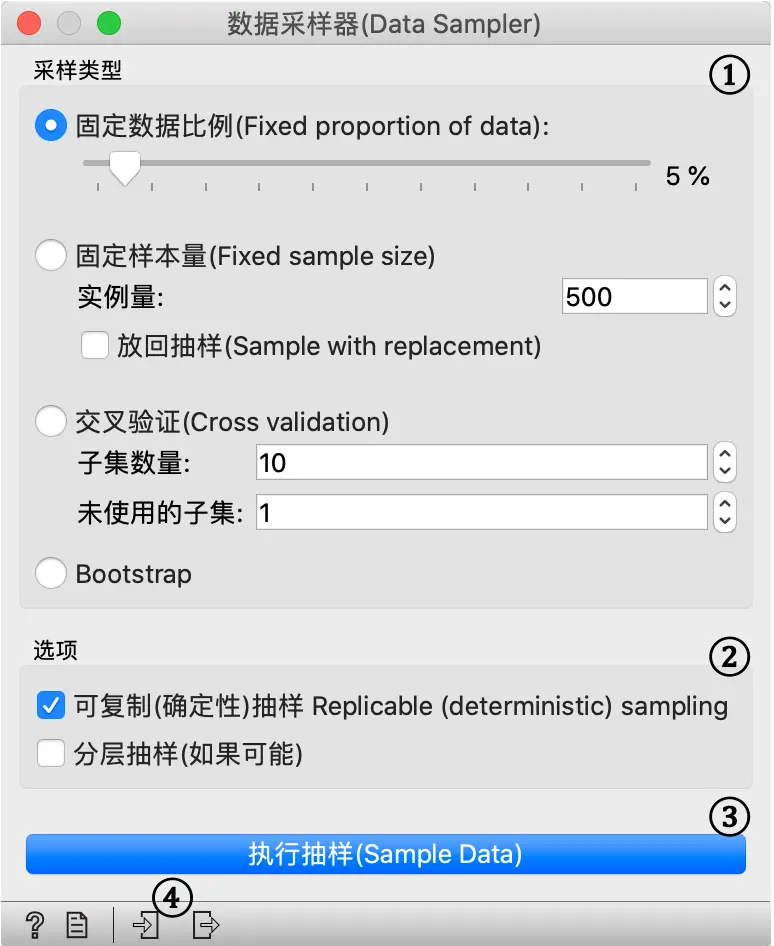
- 所需的采样方法:
- 可复制(确定性)抽样 保持了可跨用户携带的抽样模式,而 分层抽样 则模仿了输入数据集的组成。
- 点击 ”执行抽样“ 输出数据样本
- 有关输入和输出数据集的信息。
如果选择了所有数据实例(通过将比例设置为100%或将固定样本大小设置为整个数据大小),输出数据仍会会重排。
实例
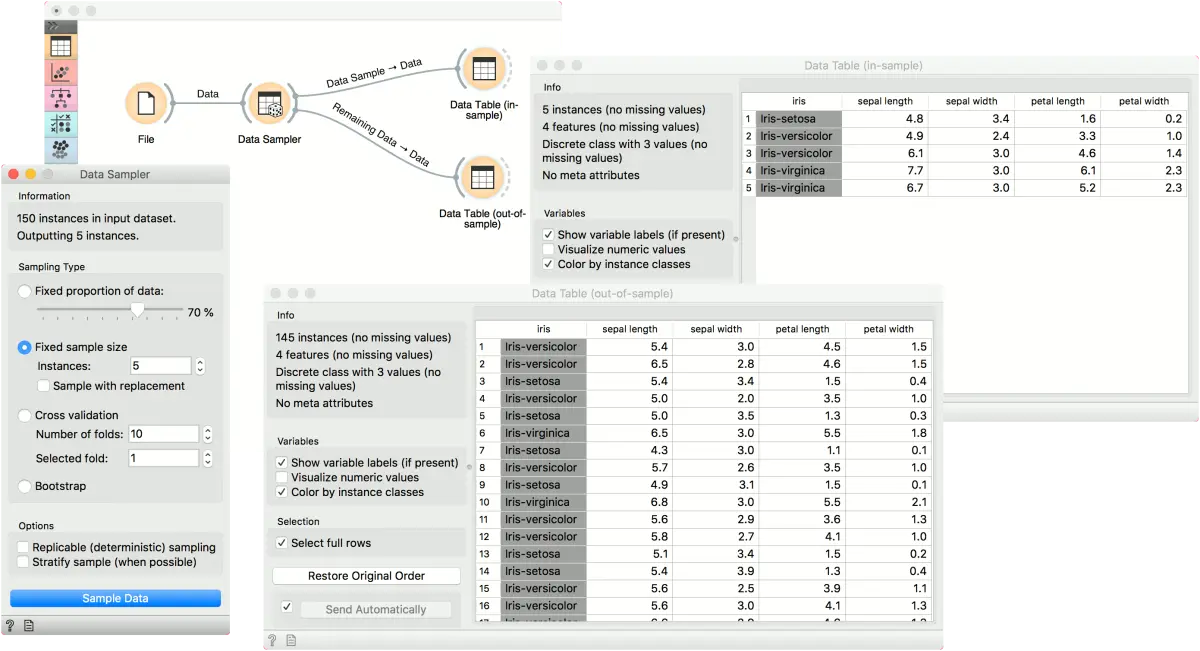
首先,让我们看看数据采集器(Data Sampler)的工作原理。 我们将使用文件(File)小部件中的 irsi 数据集。 我们看到数据中有 150 个实例。 我们使用 数据采集器(Data Sampler 小部件对数据进行了采样,为简单起见,我们选择使用5个实例的固定样本大小进行采样。 我们可以在数据表(Data Table)小部件中观察采样数据。 第二个数据表(Data Table)显示了样本中没有的其余 145 个实例。 要输出样本外数据,请双击小部件之间的连接,然后将输出重新连接到 “剩余数据–>数据”。
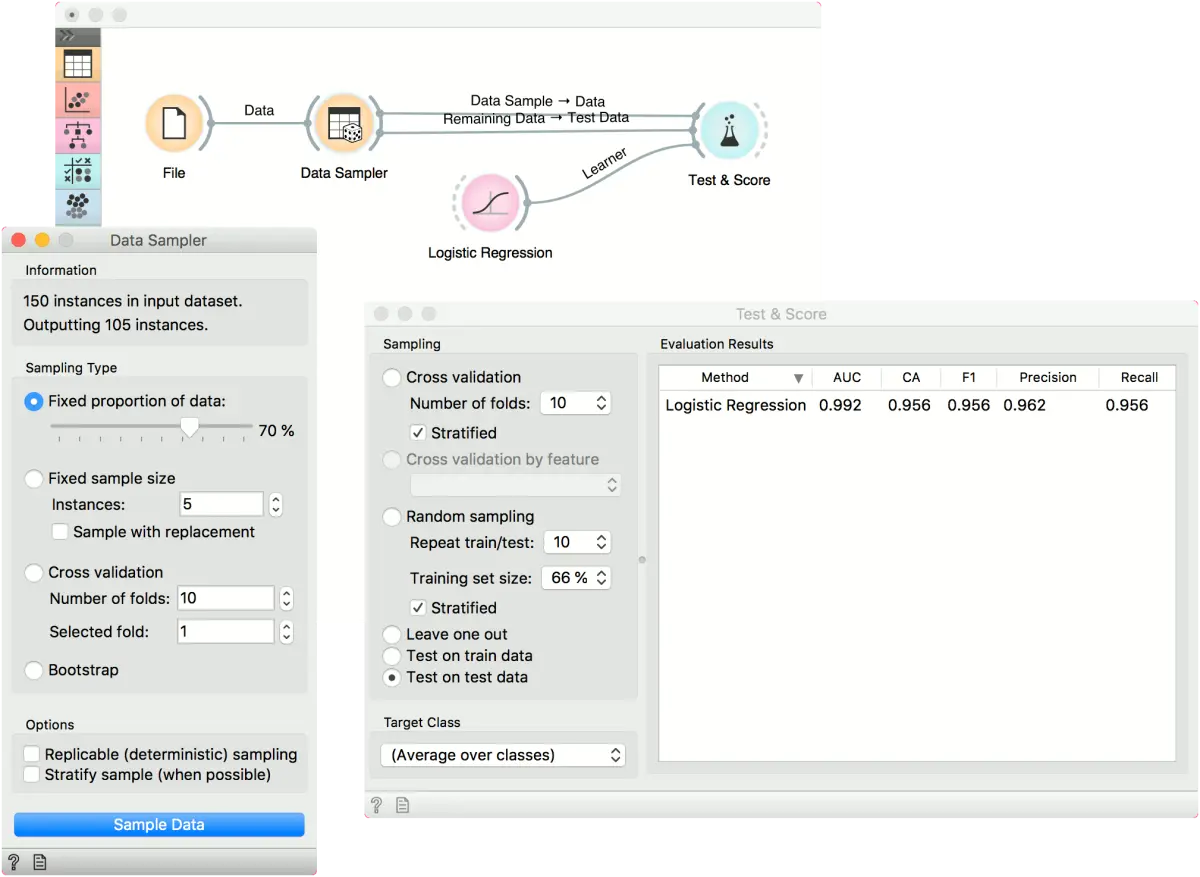
现在,我们使用数据采集器(Data Sampler)将数据分为训练和测试部分。我们使用 iris 数据集,该数据已与文件(File)小部件一起加载。 在 数据采集器(Data Sampler)中,我们以固定比例拆分数据,将 70% 的数据实例保留在样本中。
然后,我们将两个输出连接到 测试与评分(Test & Score) “剩余数据”->“测试数据”`。 最后,我们添加了逻辑回归(Logistic Regression)数据评估结果。
过采样/欠采样
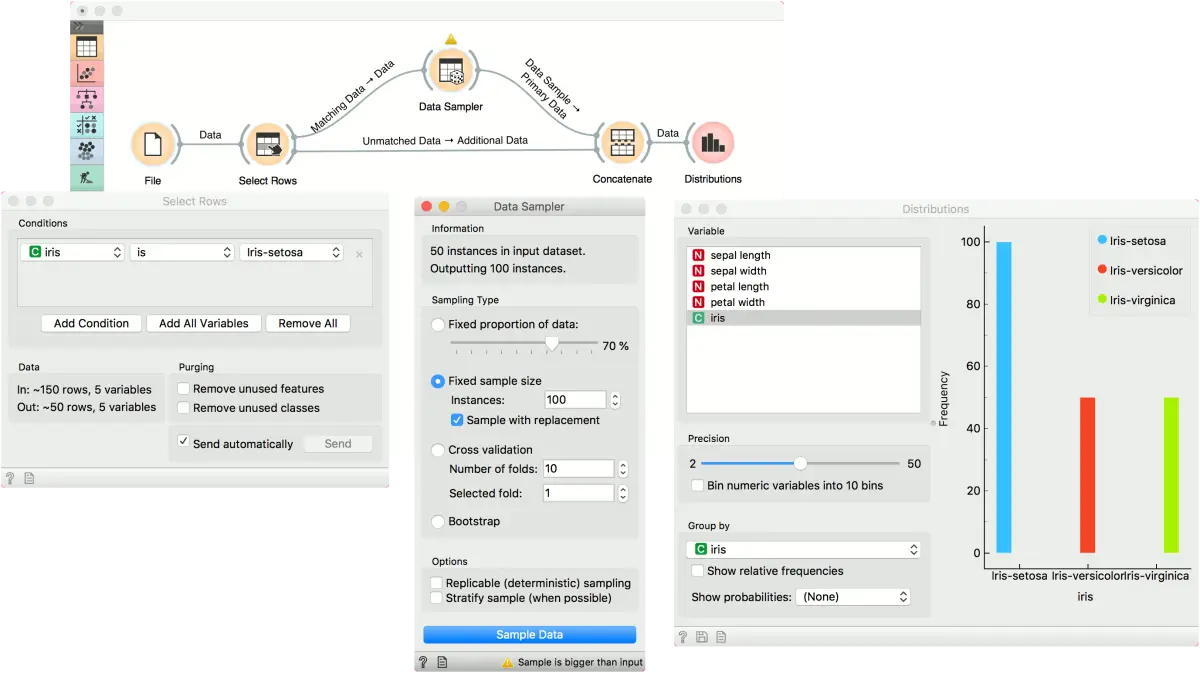
数据采样器还可以用于对数据中的少数分类过采样或多数分类进行欠采样。这里展示一个过采样的例子。 首先,使用 选择行(Select Rows)小部件分割少数类。 我们使用 文件(File)小部件中的 iris 数据。 数据集具有 150 个数据实例,每个类别 50 个。 对 iris-setosa 进行过采样。
在选择行(Select Rows)小部件中,将条件设置为 iris is iris-setosa。 这将输出 iris-setosa 类的 50 个实例。 现在,将 匹配数据 连接到 数据采样器,选择 固定样本量,将其设置为 100,然后选择 替换样本。 按下 执行抽样 后,小部件将输出 100 个 iris-setosa 类实例,其中一些实例将重复(因为我们使用放回抽样)。
最后,使用 连接(Concatenate)将过采样的实例和选择行(Select Rows)小部件输出的 不匹配数据 连接。 这将输出包含 200 个实例的数据集。 我们可以在分布(Distributions)小部件中观察最终结果。
反馈问题
文档有问题? 或者有其他意见和建议? 请在本文档的 Github 仓库直接反馈
点我反馈进入反馈页面不知道如何反馈, 请点击这里