合并数据(Merge Data)
根据选定属性的值合并两个数据集。
输入
- 主数据: 输入的主数据集
- 附加数据: 附加数据集
输出
- 数据:从附加数据添加特征的数据集
功能
合并数据(Merge Data) 小部件用于根据选定属性(列)的值横向合并两个数据集。在输入中,需要两个数据集,即主数据和附加数据。来自两个数据集的行与用户选择的属性值匹配。 小部件产生一个输出。 它对应于输入数据的实例,来自输入的附加数据的属性(列)填加到该实例。
如果所选属性对不包含唯一值(换句话说,属性具有重复值),则小部件将发出警告。相反,一个可以匹配多个属性。单击加号图标以添加要合并的属性。最终结果必须是每一行的唯一组合。
界面
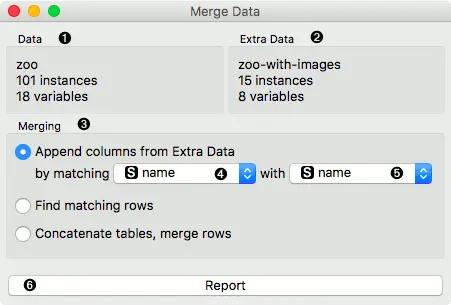
- 主数据的信息。
- 附加数据的信息。
- 合并类型:
- 从附加数据添加列 将输出主数据中的所有行,并增加附加数据中的列。如果附加数据没有对应的匹配数据,则会添加空字段。
- 寻找匹配行,从数据中输出行,并在“附加数据”中增加列。 不匹配的行将从输出中删除。
- 连接表格对称地处理两个数据源。 输出与第一个选项相似,不同之处在于,来自附加数据的不匹配值会附加在末尾。
- 数据输入中的属性列表。
- 来自“附加数据”输入的属性列表。
- 产生报告。
合并类型
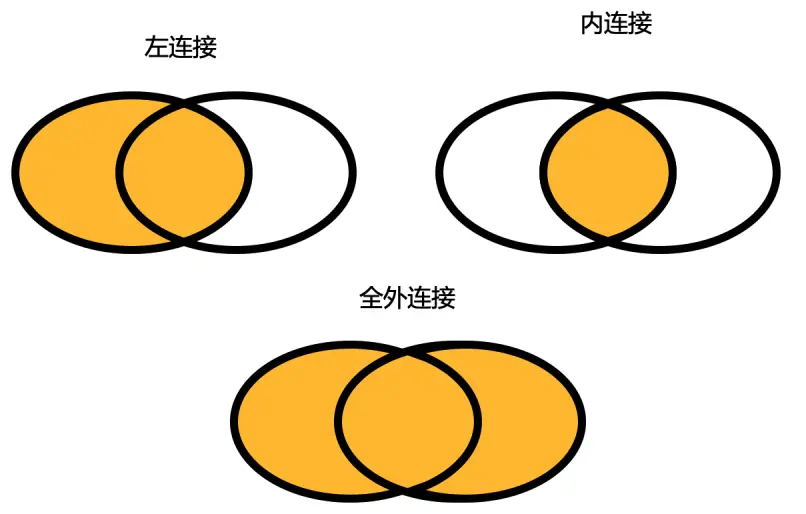
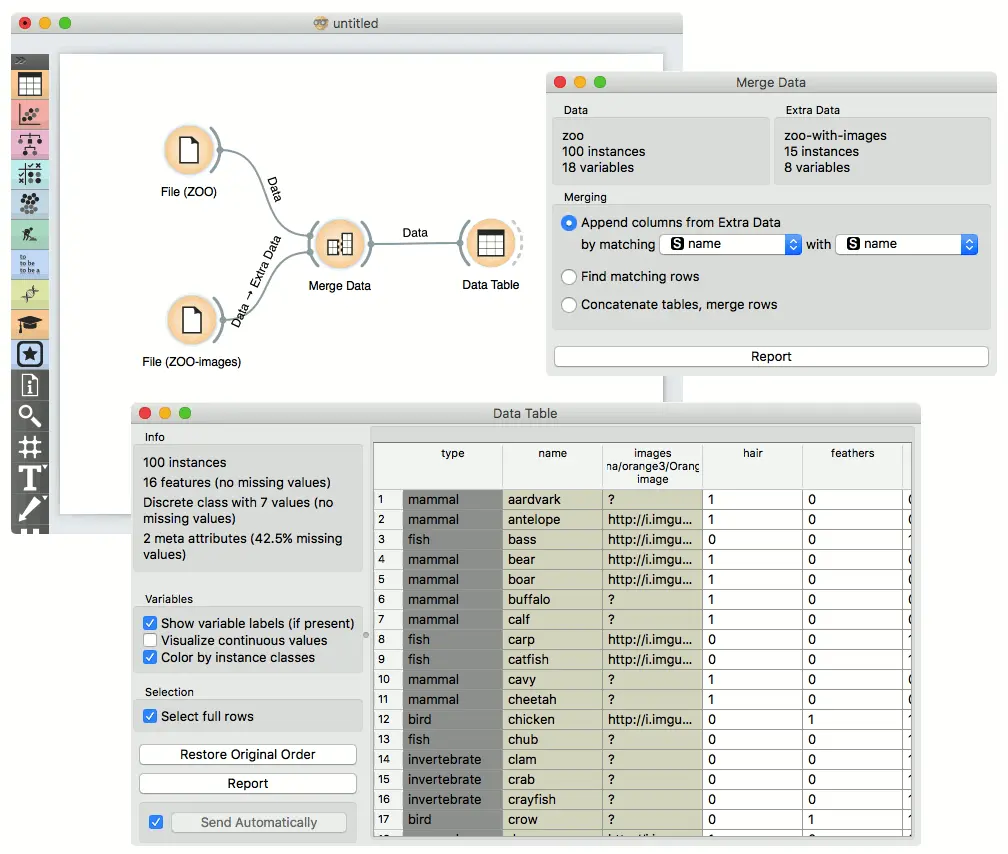
从附加数据添加列(左联接)
附加数据中的列将添加到主数据中。没有匹配行的实例将添加缺失值。
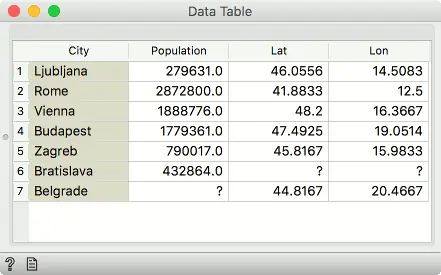
例如,第一个表包含城市名称,第二个表是城市及其坐标的列表。然后将具有坐标的列添加到具有城市名称的数据中。 如果城市名称无法匹配,则会出现缺失值。
在我们的示例中,第一个数据输入包含6个城市,但是"附加数据"没有提供 Bratislava (布拉迪斯拉发)的纬度和经度值,因此这些字段将为空。
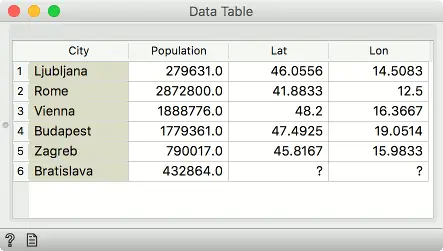
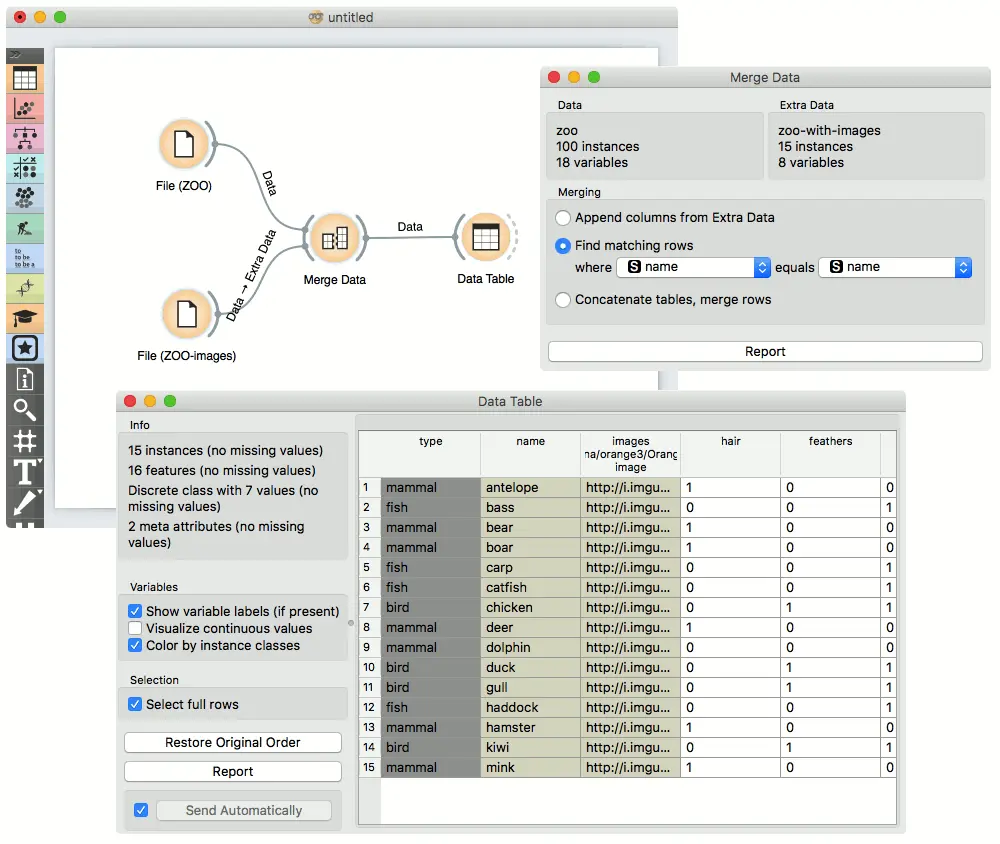
寻找匹配行(内部联接)
只有匹配的那些行将出现在输出中,并填加“附加数据”列。 没有匹配项的行将被删除。
在我们的示例中,“主数据”输入中的 Bratislava (布拉迪斯拉发)没有纬度和经度值,而在合并中的“城市”列中找不到 “附加数据” 中的 Belgrade(贝尔格莱德)。 因此,两个实例都被删除-仅实例的交集被发送到输出。
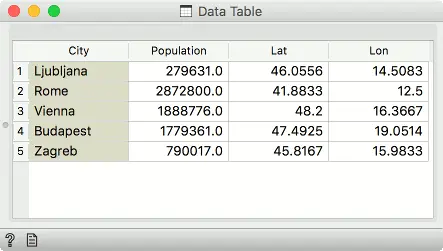
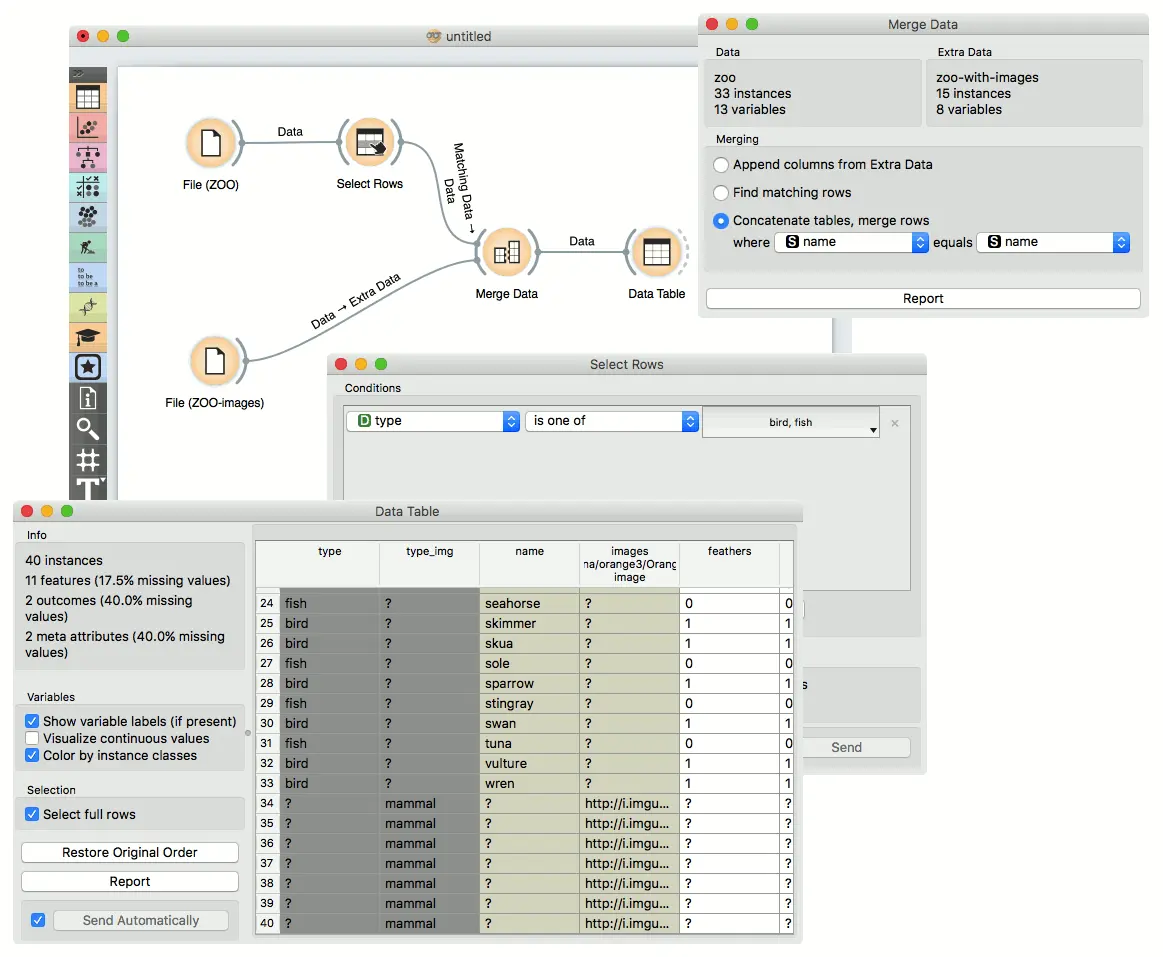
连接表格(外部联接)
来自主数据和附加数据的行将出现在输出中。如果行无法匹配,则会出现缺失值。 在我们的示例中,Bratislava (布拉迪斯拉发)和Belgrade(贝尔格莱德)现在都存在。 布拉迪斯拉发将缺少纬度和经度值,而贝尔格莱德将缺少人口值。
行索引
数据将按照表中出现的顺序进行合并。来自主数据输入的行号1将与来自附加数据输入的行号1合并。行号由橙现智能根据数据实例的原始顺序分配。
实例ID
这是一个更复杂的选项。有时,在分析和域中转换的数据不再相同。 但是,原始行索引仍在后台存在(橙现智能会记住它们)。在这种情况下,可以合并实例ID。 例如,如果您使用 PCA 转换了数据,在”散点图“中将其可视化,选择了一些数据实例,现在您希望查看所选子集的原始信息。将”散点图的“输出连接到合并数据,将原始数据集添加为附加数据,然后按实例ID合并。
由两个或多个属性合并
有时我们的数据实例对于列的组合而不是单个列是唯一的。要合并多个列,请按匹配条件旁边的加号,添加行匹配条件。 要删除它,请按 x。
在下面的示例中,我们将按学生列和班级列进行合并。
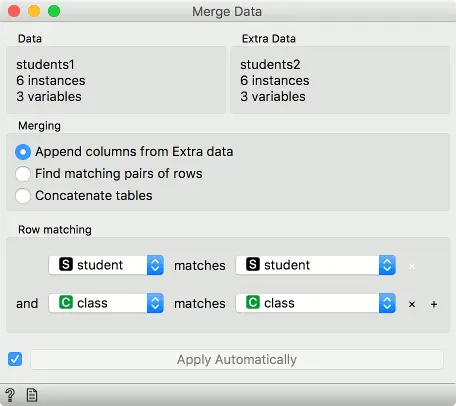
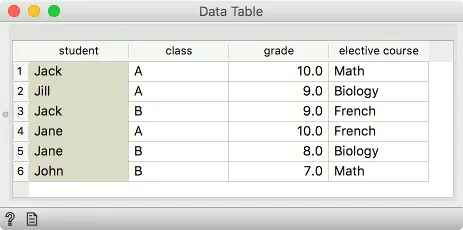
假设我们有两个数据集,分别包含学生姓名和所属班级。第一个数据集包含学生的成绩,第二个数据集包含他们选择的选修课。 不幸的是,我们的数据中有两个Jack,一个来自A类,另一个来自B类。Jane同样。 为了区分两者,我们可以在学生姓名和班级上都匹配行。
示例
合并两个数据集会导致基于选定的共同属性将新属性附加到原始文件中。在下面的示例中,我们希望将仅包含事实数据的 zoo.tab 文件与包含图像的 zoo-with-images.tab 合并。两个文件共享一个通用的字符串属性 name。 现在,我们创建一个连接两个文件的工作流程。 zoo.tab 数据连接到 “合并数据(Merge Data)” 小部件的 “主数据” 输入,而 zoo-with-images.tab 数据连接到 “附加数据” 输入。 然后,“合并数据(Merge Data)”小部件的输出将连接到 数据表(Data Table) 小部件。 在后者中,显示了合并数据通道,其中将图像属性添加到了原始数据。
下面的工作流程显示了我们要在输出中包括所有实例的情况,甚至包括那些未找到按 name 匹配的实例的情况。
在下一个工作流程中显示了第三种合并。 输出由两个输入组成,并在找不到匹配项的情况下分配了未知值。
反馈问题
文档有问题? 或者有其他意见和建议? 请在本文档的 Github 仓库直接反馈
点我反馈进入反馈页面不知道如何反馈, 请点击这里