异常值(Outliers)
异常值检测小部件。
输入
- 数据:输入数据集
输出
- 正常值:实例未计为异常值
- 异常值:实例记为异常值
- 数据:输入数据集附加了异常值变量
功能
异常值(Outliers) 小部件可应用四种方法进行异常值检测。所有方法都对数据进行分类。具有非线性内核(RBF)的 One Class SVM在非高斯分布情况下表现良好,而Covariance estimator仅适用于高斯分布的数据。对中等高维数据集执行异常值检测比较有效的方法方法是使用Local Outlier Factor算法。该算法计算出一个得分反映观测异常的程度。它测量给定数据点相对于其相邻点的局部密度偏差。在高维数据集中执行异常值检测的另一种有效方法是使用 random forests(随机森林)方法。
界面
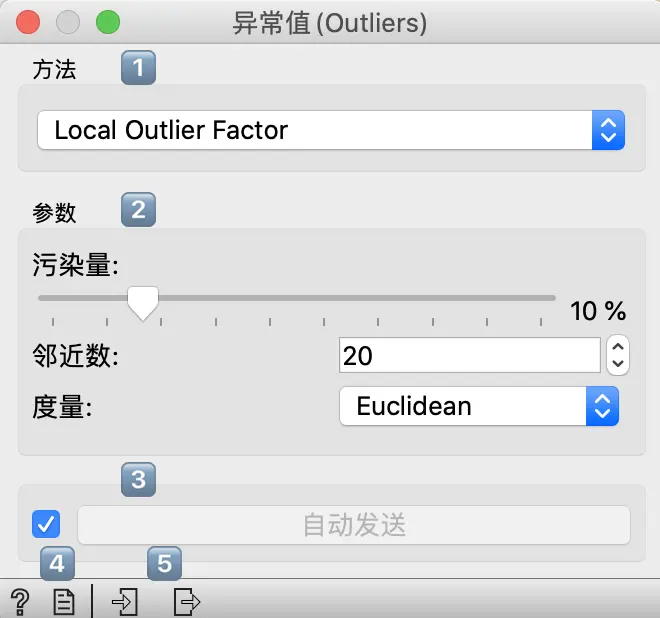
- 异常值检测方法:
- 设置方法的参数:
- 具有非线性内核(RBF)的One Class SVM:将数据分类为与核心类相似或不同:
Nu是训练误差分数的上限和支持向量分数的下限的参数Kernel coefficient是一个伽玛参数,它指定单个数据实例的影响程度
- 协方差估计器(Covariance Estimator):使用曼哈顿距离度量将省略号拟合到中心点:
污染量是数据集中异常值的比例支持比例指定所包含的估计比例
- 局部异常因子(Local Outlier Factor):从k近邻获得局部密度:
污染量是数据集中异常值的比例邻近数代表邻居数量度量是距离度量
- 隔离森林(Isolation Forest):通过随机选择特征,然后随机选择所选特征的最大值和最小值之间的分割值来隔离观测值:
污染量是数据集中异常值的比例可重复训练固定随机种子
- 具有非线性内核(RBF)的One Class SVM:将数据分类为与核心类相似或不同:
- 如果勾选了 ”自动应用“,则更改将自动传送。或者,单击 “应用”。
- 产生报告。
- 左边为输入的实例数,右边为计为正常值的实例数。
示例
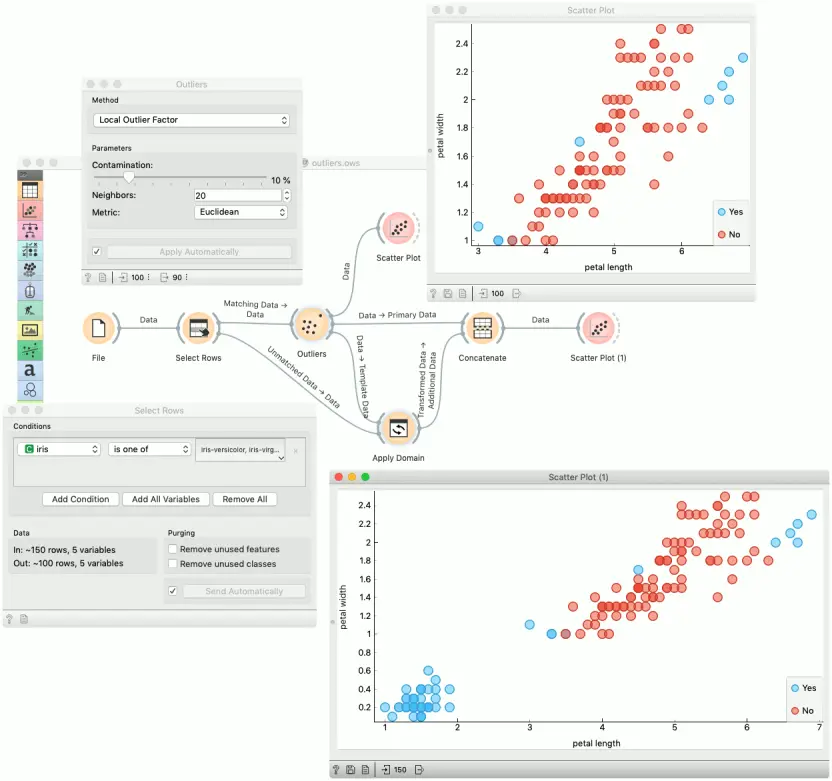
我们使用 Iris 数据集的子集(versicolor and virginica instances)来检测异常值。我们选择了使用 Euclidean(欧几里得距离)度量的Local Outlier Factor方法。然后,我们在散点图Scatter Plot小部件中观察带注释的实例。
下一步,我们使用 setosa 实例通过 应用变换(Apply Domain)小部件演示新颖性检测。连接两个输出后,我们在 散点图(1) 检查异常值。
反馈问题
文档有问题? 或者有其他意见和建议? 请在本文档的 Github 仓库直接反馈
点我反馈进入反馈页面不知道如何反馈, 请点击这里