预处理(Preprocess)
使用选定的方法预处理数据。
输入
- 数据:输入数据集
输出
- 预处理器:预处理方法
- 预处理数据:使用选定方法进行预处理的数据
功能
预处理(Preprocess) 对于获得更高质量的分析结果至关重要。预处理(Preprocess)小部件提供了可使用一个预处理流水线,这个流水线可以结合几种预处理方法。某些方法可以作为单独的小部件使用,它们提供了更高级的技术和更完善的参数调整。
界面
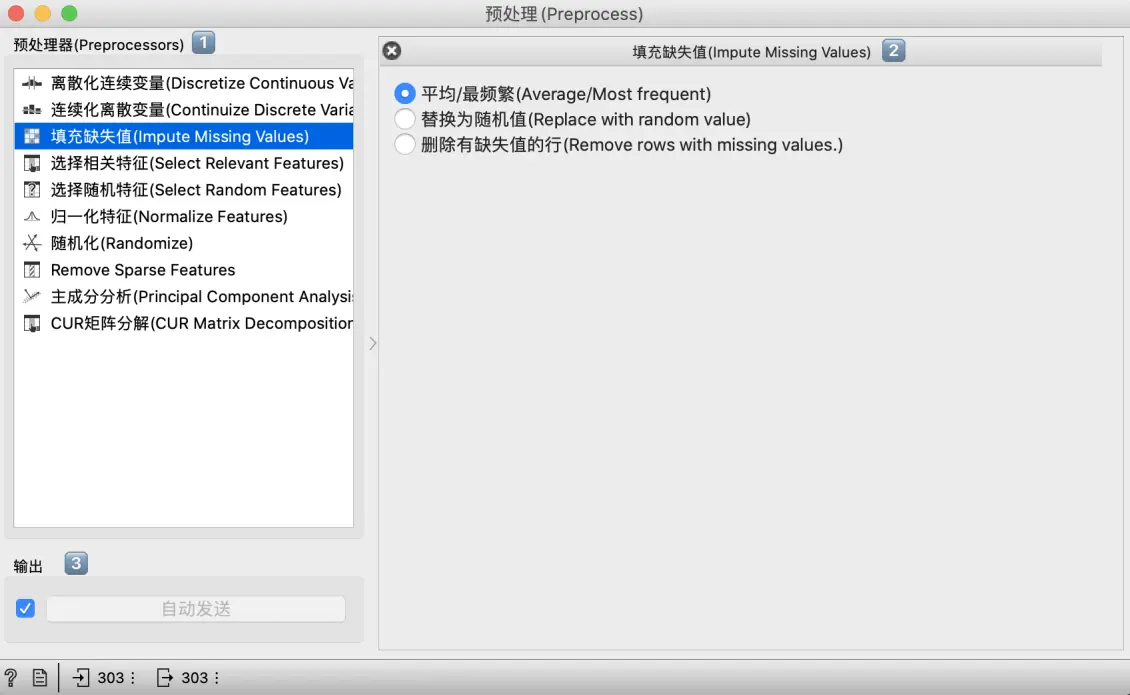
- 预处理器列表。双击要使用的预处理器,然后通过上下拖动来排序。也可以通过从左侧菜单向右拖动预处理器来添加它们。
- 预处理流水线
- 勾选框(自动发送)后,小部件将自动传送更改。或者,点击”发送“按钮。
预处理器

离散化连续变量
- Fayyad 和 Irani 提出的 熵 MDL 离散化(Entropy-MDL discretization) 使用 期望信息(expected information) 决定柱子(bin)的宽度。
等频离散化按频率划分(每个柱子(bin)中的实例数相同)。等宽离散化会创建等宽度的条(每个柱子(bin)的跨度相同)。- 完全删除数字功能。
连续化离散变量
最常见的为基会将最常见的离散值视为 0,将其他视为1。具有2个以上值的离散属性的话,最常使用的离散属性将被视为基,并与相应列中的其余值进行对比。每一个值一个特征为每个值创建列,在实例中包含该值的地方放置1,不包含该值的地方放置0。其实就是独热编码。删除非二进制特征:仅保留值为 0 或 1 的分类特征并将其转换为连续的值。删除分类特征:完全删除分类特征。按有序数据处理:将离散值视为数字。如果离散值是分类,则将为每个分类按照数据中出现的次序分配一个数字。除以取值数目类似于按有序数据处理,但最终值将除以值的总数,因此新的连续变量的范围将为[0,1]。
填充缺失值
平均/最频繁:将平均值(连续)或最频繁值(离散)替换缺失值(NaN)。替换为随机值:将缺失值替换为每个变量范围内的随机值。删除有缺失值的行
选择相关特征:
- 与排名(Rank)小部件相似,此预处理器仅输出最有用的特征。评分方法:信息增益,增益比,基尼系数,ReliefF,fast correlation based filter,ANOVA, Chi2, RReliefF,和单变量线性回归。
特征的数量是指输出中应包含多少变量。固定:返回固定数量的得分最高的变量,百分比:返回所选特征的最高百分比。

选择随机特征:
会从原始数据中输出固定数量的特征或一个百分比。这主要用于高级测试和教育目的。
归一化特征:
将值调整为一个共同范围。通过均值或中中位数或完全省略中心来确定中心值。与缩放类似,可以按标准差,按跨度或根本不按比例进行缩放。
随机化
随机化会打乱类别,并破坏实例与类别之间的连接。同样,可以将特征或元数据随机化。如果启用了 可复制混排,则可以使用保存的工作流程共享和重复随机结果。这主要用于高级测试和教育目的。
删除稀疏特征
删除稀疏特征将保留具有超过用户定义阈值百分比的非零值的特征。其余的将被丢弃。
主成分分析
输出PCA转换的结果。类似于PCA小部件。
CUR矩阵分解是一种降维方法,类似于SVD。
示例
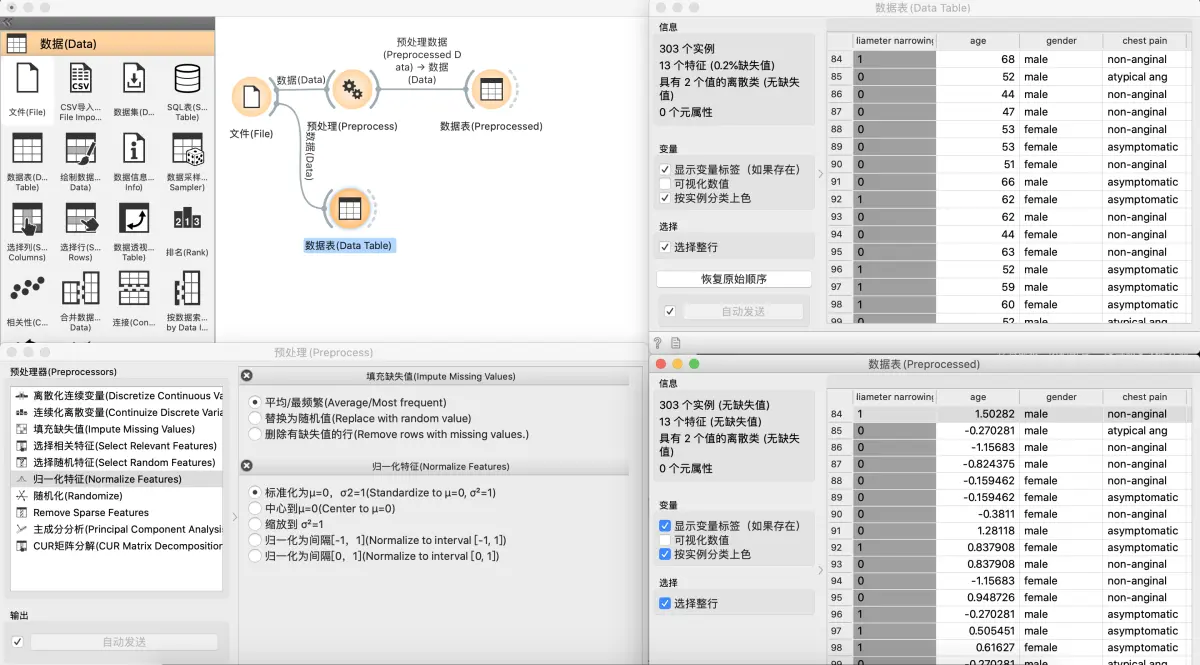
第一个示例
我们使用了文件(File)小部件的下拉菜单中可用的 heart_disease.tab 数据集。然后我们使用 预处理(Preprocess) 小部件来填充缺失值并标准化特征。我们可以在数据表(Data Table)观察变化,并将其与未处理的数据进行比较。
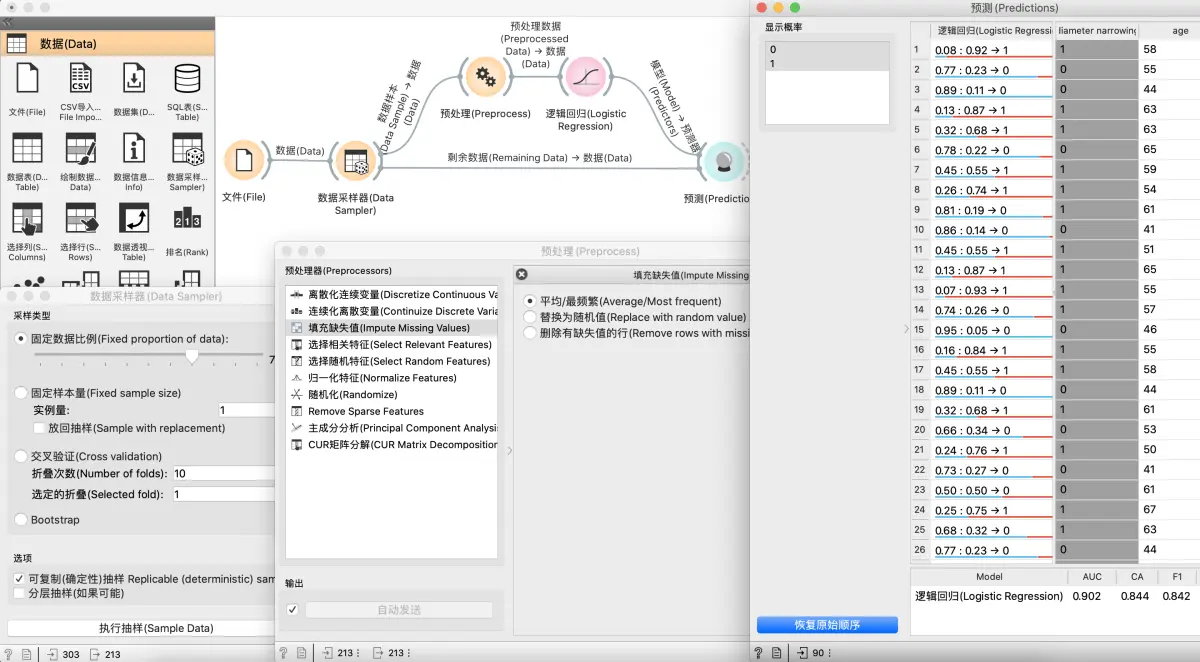
第二个示例
我们展示了如何使用 预处理(Preprocess) 进行预测建模。
我们使用文件(File)小部件中的 heart_disease.tab (心脏病)数据。可以通过下拉菜单访问数据。这是一个包含 303 名胸痛患者的数据集。测试完成后,发现一些患者的直径变窄(diameter narrowing),而其他患者则没有(这是我们的类别变量)。
心脏病数据缺少一些值,我们希望考虑到这个情况。
- 首先,我们将使用数据采样器(Data Sampler) 将数据集分为训练数据和测试数据。
- 然后我们将数据样本发送到 预处理(Preprocess)。我们将使用
填充缺失值预处理器,但是您可以在数据上尝试使用任何预处理器组合。我们将预处理数据发送给逻辑回归(Logistic Regression) 小部件,构建模型并预测。 - 最后,预测(Predictions)还需要数据进行预测。我们将使用数据采样器(Data Sampler)的输出进行预测,但这一次不是数据样本,而是剩余数据,这是未用于训练模型的数据。
请注意,我们如何将剩余数据直接发送到预测(Predictions),而不进行任何预处理。这是因为橙现智能会在内部对新数据预处理,以防止模型构造中的任何错误。与训练数据完全相同的预处理过程将用于预测。相同的过程适用于测试和评分(Test & Score)。
反馈问题
文档有问题? 或者有其他意见和建议? 请在本文档的 Github 仓库直接反馈
点我反馈进入反馈页面不知道如何反馈, 请点击这里