堆叠(Stacking)
堆叠多个模型。
输入
- 数据:输入数据集
-
预处理器:预处理方法
- 学习器:学习算法
- 组合方法:模型组合方法
输出
- 学习器:组合的学习算法
- 模型:训练过的模
功能
堆叠(Stacking) 是一种集成方法,可以从多个基本模型计算出元模型。 堆叠(Stacking) 小部件具有 组合方法 输入,它提供了一种用于组合输入模型的方法。如果未提供 组合方法 输入,则使用默认方法:用于分类的 “逻辑回归” 和用于回归问题的 “岭回归”。
界面
- 可以给学习器一个名称,该名称将出现在其他小部件中。 默认名称是“堆叠(Stacking)”
- 发送报告
- 勾选 “自动应用” 以自动传送对其他小部件的更改,并在连接学习数据后立即训练分类器。 或者,在配置后按 “应用”。
示例
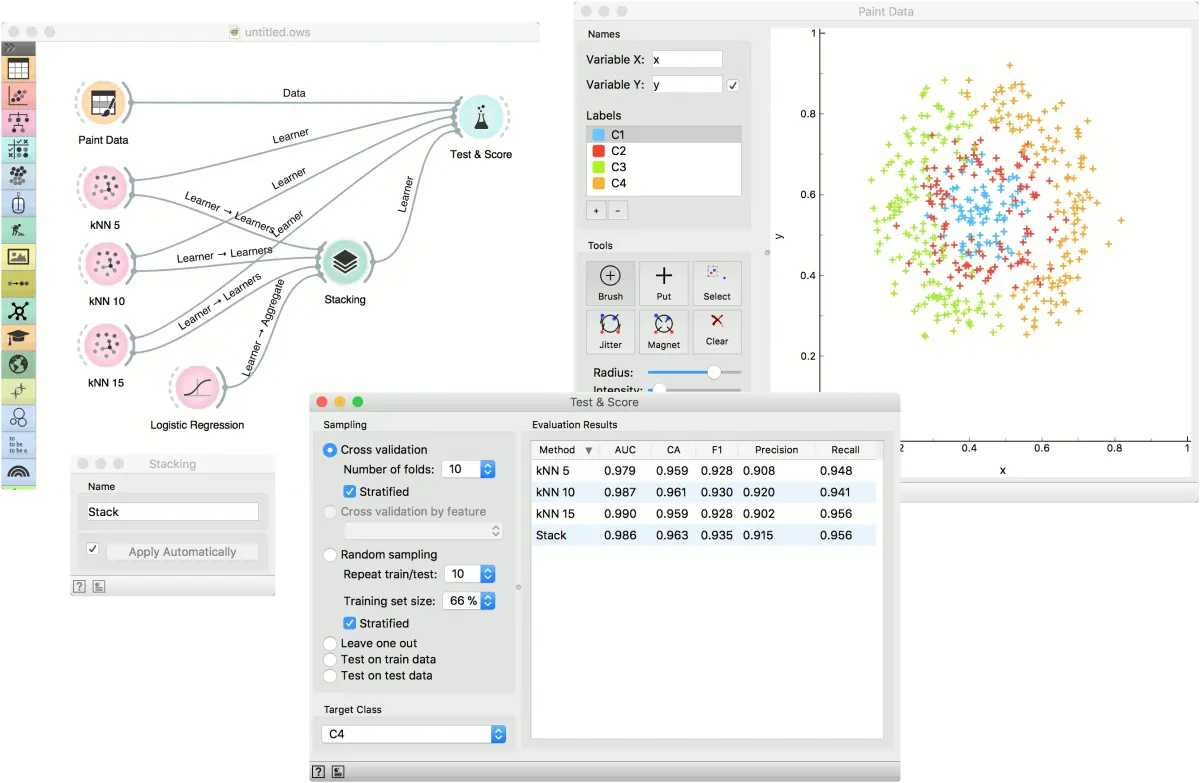
我们将使用绘制数据(Paint Data)演示如何使用小部件。我们绘制了一个带有4个类别标签的复杂数据集,并将其发送到测试与评分(Test & Score)。 我们还提供了三个k 近邻(kNN)学习器,每个学习器具有不同的参数(邻居数为 5、10 或 15)。 评估结果不错,但是我们可以做得更好吗?
让我们使用 堆叠(Stacking) 。堆叠(Stacking) 要求输入的多个学习器和一种组合方法。在我们的例子中,这是逻辑回归(Logistic Regression)。 然后,将构建的元学习器发送到 测试与评分(Test & Score)。 即使只是微不足道的结果也有所改善。 堆叠(Stacking) 通常可以在复杂的数据集上很好地工作。
反馈问题
文档有问题? 或者有其他意见和建议? 请在本文档的 Github 仓库直接反馈
点我反馈进入反馈页面不知道如何反馈, 请点击这里