查重(Duplicate Detection)
从语料库中检测和删除重复的内容。
输入
- 距离: 距离矩阵。
输出
- 无重复语料库: 去除重复的语料库。
- 重复簇: 属于所选簇的文档。
- 语料库: 带有附加簇标签的语料库。
功能
查重(Duplicate Detection)使用聚类来查找语料库中的重复内容。它与Twitter小工具一起使用,可以很好地去除转发和其他相似文档。
要设置相似程度,在图中向左或向右拖动竖直线。该线越左,文档必须越相似才能被认为是重复的。您也可以在控制区手动设置阈值。
界面
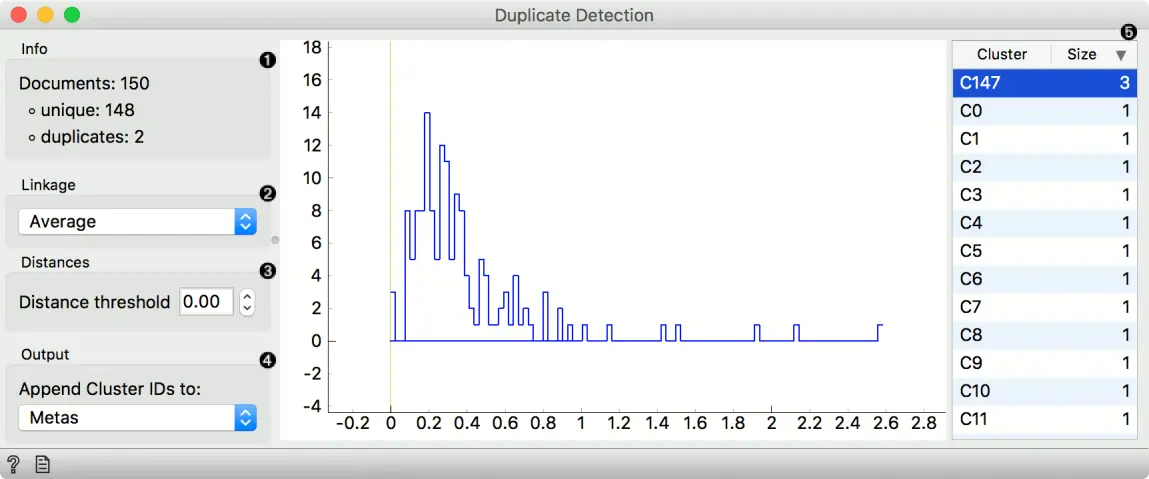
- 唯一文件和重复文件的信息。
- 用于聚类的连接(单一、平均、完整、加权和Ward)。
- 距离阈值设置相似度截止值。该值越低,数据实例必须越相似才能属于同一个聚类。你也可以通过拖动图中的垂直线来设置截止值。
- 聚类标签可以附加为属性、类或元。
- 所选阈值处的聚类列表。它们默认是按大小排序的。点击聚类来观察其输出上的内容。
示例
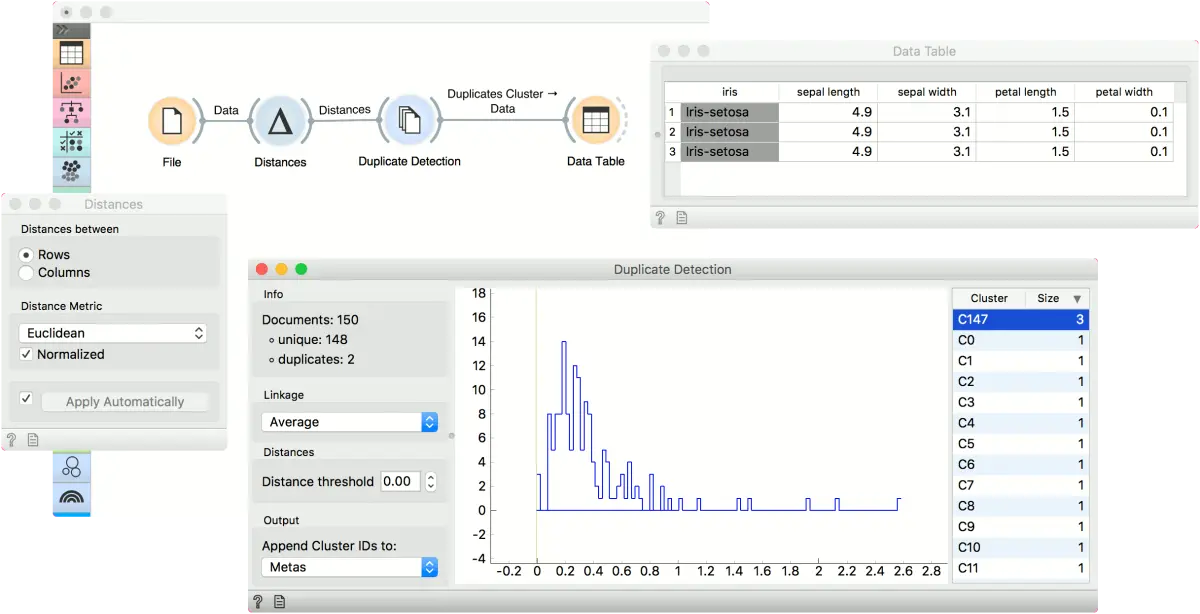
这个简单的例子使用 iris 数据来查找相同的数据实例。使用 文件 小部件加载 iris 并将其传递给 距离小部件。在距离小部件中,使用欧氏距离来计算距离矩阵。将距离传给 查重(Duplicate Detection)。
看起来簇 C147 包含三个重复的条目。让我们在小部件中选择它并在数据表中观察它。记得将输出设置为 重复簇 。这三个数据实例是相同的。要使用没有重复的数据集,请使用第一个输出,无重复语料。
反馈问题
文档有问题? 或者有其他意见和建议? 请在本文档的 Github 仓库直接反馈
点我反馈进入反馈页面不知道如何反馈, 请点击这里