文本预处理(Preprocess Text)
用选定的方法对语料进行预处理。
输入
- 语料库: 文件集。
输出
- 语料库: 预处理过的语料库。
功能
文本预处理(Preprocess Text)将您的文本分割成更小的单元(标记),对它们进行过滤,运行归一化(词干、词法化),创建n-grams,并用part-of-speech标签标记。分析中的步骤是按顺序应用的,可以重新排序。点击并拖动预处理程序来改变顺序。
界面
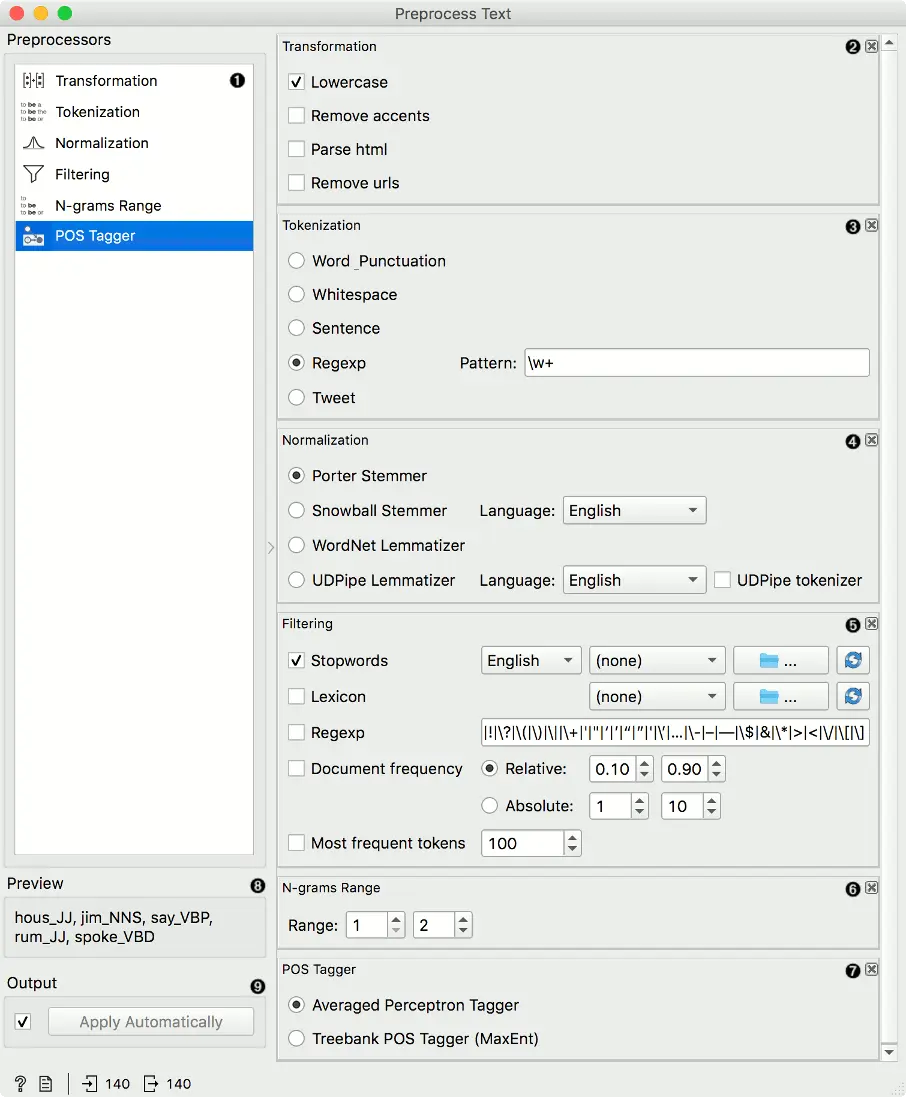
- 可用的预处理器。
- 变换对输入数据进行转换。它默认应用小写转换。
转为小写将所有文本转为小写。去除音调符号将删除文本中的所有重音/符号。 naïve → naive去除 html 标签将检测html标签并只解析出文本。 <a href…>Some text</a> → Some text(一些文本)去除 urls将从文本中删除 urls。 这个网址是 https://chengxianzn.one/。→ 这个网址是。
- 分词是将文本分解成更小的成分(单词、句子等)的方法。
单词 标点将按单词来分割文本,并保留标点符号。 his example. → (This), (example), (.)空白将只用空白(空格, 制表符等)来分割文本。 his example. → (This), (example.)句子将按句号分割文本,只保留完整的句子。 This example. Another example. → (This example.), (Another example.)- 正则表达式将通过提供的正则表达式来分割文本。默认情况下,它只按单词分割(省略标点符号)。
推特分词将通过预先训练的 Twitter 模型分割文本,该模型保留了标签、表情符号和其他特殊符号。 This example. :-) #simple → (This), (example), (.), (:-)), (#simple)
- 规一化对单词进行词干和词素化。(I’ve always loved cats. → I have alway love cat.)对于英语以外的语言,使用Snowball Stemmer(在其NLTK实现中提供可用的语言)。**
- Porter Stemmer applies the original Porter stemmer.
- Snowball Stemmer applies an improved version of Porter stemmer (Porter2). Set the language for normalization, default is English.
- WordNet Lemmatizer applies a networks of cognitive synonyms to tokens based on a large lexical database of English.
- 过滤删除或保留部分词语。
-
停用词删除文本中的停用词(如删除’and’、’or’、’in’…)。选择要过滤的语言,英语被设置为默认。您也可以加载您自己的停顿字列表,提供一个简单的 *.txt文件,每行一个停用字。
点击 “浏览 “图标,选择包含停用词的文件。如果文件已被正确加载,其名称将显示在预加载的停用词旁。如果您希望只过滤掉所提供的停用词,请将
英语改为无。点击 重新加载 图标,重新加载停用词列表。 词典只保留文件中提供的单词。加载一个 *.txt文件,每行一个词作为词库使用。点击 重新加载 图标来重新加载词库。正则表达式删除符合正则表达式的单词。默认设置为删除标点符号。文档频率保留出现在不少于且不多于指定数量/百分比的文档中的标记。绝对值只保留在指定数量的文档中出现的标记。例如 DF = (3, 5)只保留在 3 个或更多和 5 个或更少文档中出现的标记。相对值只保留在指定百分比的文档中出现的标记。例如,DF = (0.3, 0.5)只保留在 30% 到 50% 的文档中出现的标记。最常见词只保留指定数量的最常出现的词。默认值是100个最常出现的标记。
-
- N-grams 范围 创建n-grams。数字指定n-grams的范围。默认情况下返回1-gram 和 2-grams。
- POS 标记进行part-of-speech标记。
- Averaged Perceptron Tagger使用Matthew Honnibal的平均感知器标签器运行POS标签。
- Treebank POS Tagger (MaxEnt)用训练好的Penn Treebank模型运行POS标签。
- 预处理数据的预览。
- 如果自动应用开启,则会自动发送更改。或者按应用。
注意! 文本预处理(Preprocess Text) 按所列顺序应用预处理步骤。一个好的顺序是首先转换文本,然后分词、POS标记、归一化、过滤,最后根据给定的标记构建n-grams。这对于WordNet Lemmatizer尤为重要,因为它需要POS标签来进行适当的标准化。
有用的正则表达式
\bword\b: 精确匹配某个词\w+: 只配字,不配标点\b(C|c)\w+\b: 匹配以字母 c 开头的单词\w{4,}: 匹配长于4个字符的单词\b\w+(Y|y)\b: 匹配以字母 y 结尾的单词
示例
在第一个例子中,我们将观察预处理对文本的影响。我们使用的数据是 book-excerpts.tab,我们已经用语料库小部件加载了它。我们已经将 文本预处理 连接到 语料库,并保留了默认的预处理方法(小写、每个单词的标记化和停用词删除)。我们唯一增加的参数是只输出前100个最常见词。然后我们将文本预处理与词云连接起来,观察我们文本中出现频率最高的词。玩转不同的参数,看看它们是如何转换输出的。
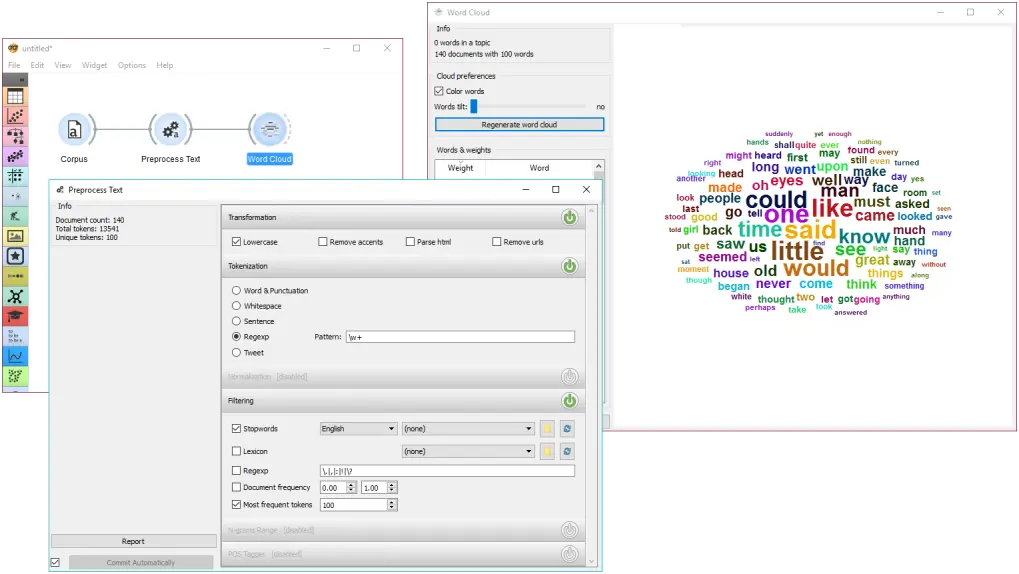
~The second example is slightly more complex. We first acquired our data with Twitter widget. We quired the internet for tweets from users @HillaryClinton and @realDonaldTrump and got their tweets from the past two weeks, 242 in total.~
~In Preprocess Text there’s Tweet tokenization available, which retains hashtags, emojis, mentions and so on. However, this tokenizer doesn’t get rid of punctuation, thus we expanded the Regexp filtering with symbols that we wanted to get rid of. We ended up with word-only tokens, which we displayed in Word Cloud. Then we created a schema for predicting author based on tweet content, which is explained in more details in the documentation for Twitter widget.~
反馈问题
文档有问题? 或者有其他意见和建议? 请在本文档的 Github 仓库直接反馈
点我反馈进入反馈页面不知道如何反馈, 请点击这里