主题模型(Topic Modelling)
使用 Latent Dirichlet Allocation、Latent Semantic Indexing或Hierarchical Dirichlet Process 进行主题建模。
输入
- 语料库: 文件集。
输出
- 语料库:附加主题权重的语料库。
- 主题: 选定的带有词权的主题。
- 所有主题: 每个主题的词权重
功能
主题模型(Topic Modelling)根据每个文档中发现的词组及其各自的频率发现语料库中的抽象主题。一个文档通常包含不同比例的多个主题,因此小工具也会报告每个文档的主题权重。
小工具包装了 gensim 的主题模型(LSI, LDA, HDP)。
第一种,LSI,可以返回正词和负词(话题中的词和非话题中的词). 同时, 话题权重可以是正的,也可以是负的。正如 gensim 的主要开发者Radim Řehůřek所说。“LSI的话题不应该是有意义的;因为LSI允许负数,所以归根结底是话题之间有微妙抵消,没有直接的方法可以解释话题。”
LDA可以更容易解释,但比LSI慢。HDP有很多参数 – 对应题目数量的参数是 Top level truncation level (T)。可以检索到的题目数量最小的是10个。
界面
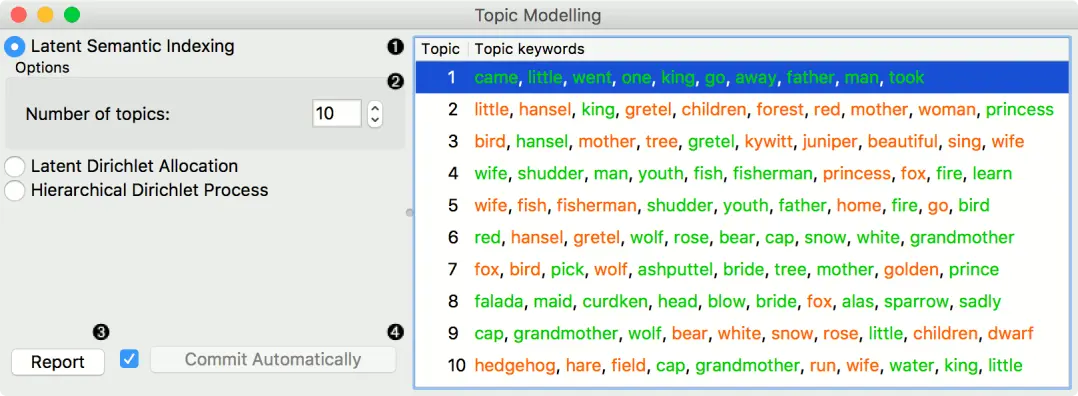
- 主题建模算法。
- Latent Semantic Indexing。返回负数词和正数词以及主题权重。
- Latent Dirichlet Allocation。
- 分层Dirichlet进程
- 算法的参数。LSI和LDA只接受建模的主题数量,默认设置为10个。但HDP的参数更多。由于该算法对计算量要求很高,我们建议您在子集上进行尝试,或者提前设置好所有需要的参数,然后才运行该算法(将输入连接到小组件)。
- 第一级集中度(γ):Dirichlet过程第一级(语料库)的分布。
- 第二级浓度(α):迪里奇特过程第二级(文件)的分布。
- 题目Dirichlet(α):浓度参数用于题目抽签。
- 顶层截断(Τ):语料库层截断(主题数)
- 第二级截断(K):文件级截断(主题数)
- 学习率(κ):步长
- 减速参数(τ)
- 制作报告。
- 如果自动发送开启,则会自动传达更改。或者按发送。
示例
探索单个话题
在第一个例子中,我们介绍了主题模型小部件的简单使用。首先,我们加载 grimm-tales-selected.tab 数据集,并使用文本预处理对单词进行分词,并删除停用词。然后我们将文本预处理连接到主题模型,我们使用简单的 Latent Semantic Indexing 在文本中找到10个主题。
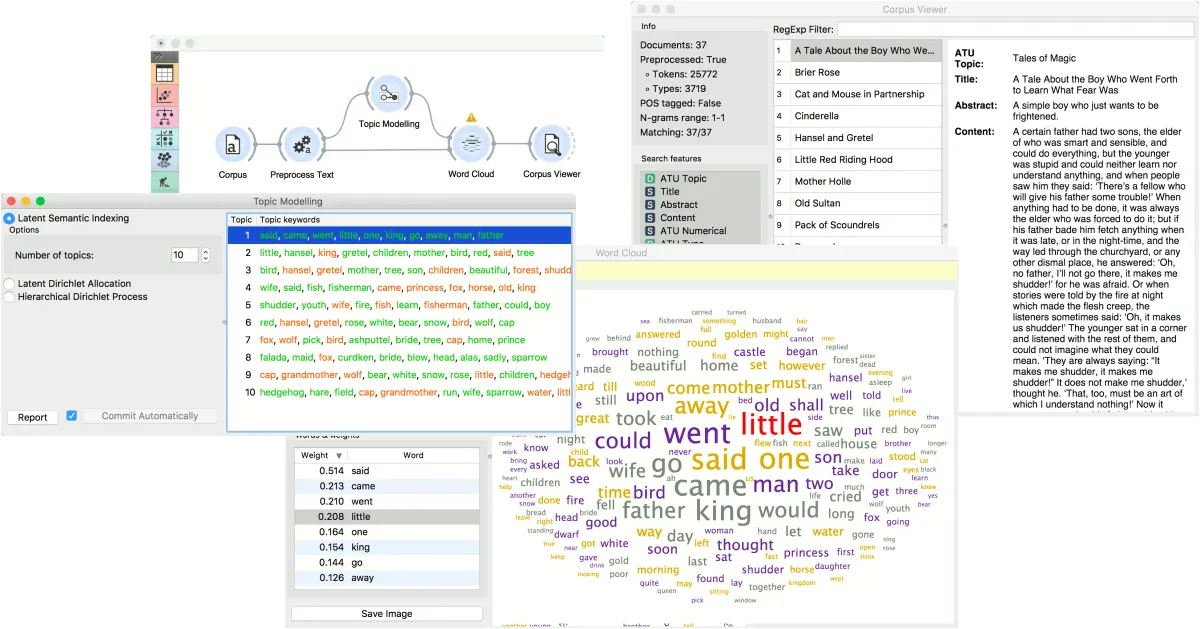
LSI为每个主题提供了正权重和负权重。正向权重意味着该词对某一主题具有很高的代表性,而负向权重则意味着该词对某一主题具有很低的代表性(该词在文本中出现的次数越少,该主题的可能性越大)。正向词被染成绿色,负向词被染成红色。
然后,我们选择第一个话题,在词云小部件中显示该话题中出现频率最高的词。为了能够输出选中的文档,我们还将文本预处理连接到词云。现在我们可以在词云中选择一个特定的词,比如说little小。它将被染成红色,同时在左侧的单词列表中高亮显示。
现在我们可以在语料查看器中观察所有包含little这个词的文档。
主题可视化
在第二个例子中,我们将考察主题和单词/文档之间的相关性。我们仍然使用 grimm-tales-selected.tab 语料库。在文本预处理中,我们使用的是默认的预处理,并附加了一个按文档频率(0.1 - 0.9)进行过滤。在主题模型中,我们使用5个主题的LDA模型。
将主题模型连接到多维尺度分析(MDS)。确保链接设置为所有主题 -> 数据。主题模型将按主题输出一个词权重矩阵。
在多维尺度分析(MDS)中,这些点现在是主题。我们将点的大小设置为Marginal topic probability,这是All Topic的额外一列–它报告的是语料库中话题的边际概率(话题在语料库中的表现强度)。
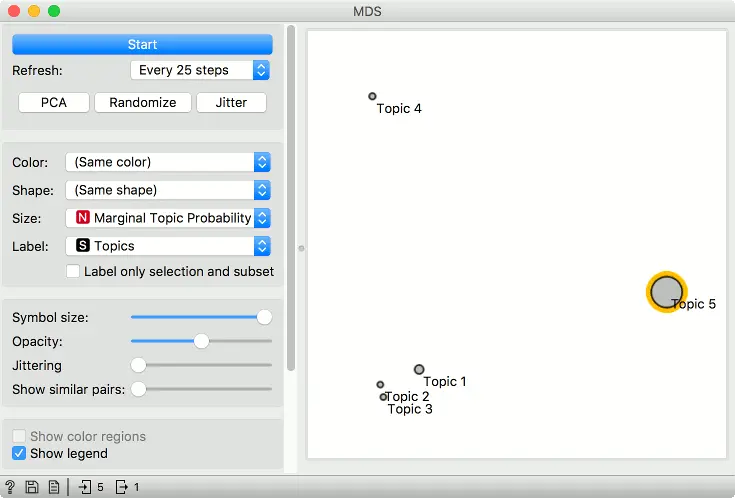
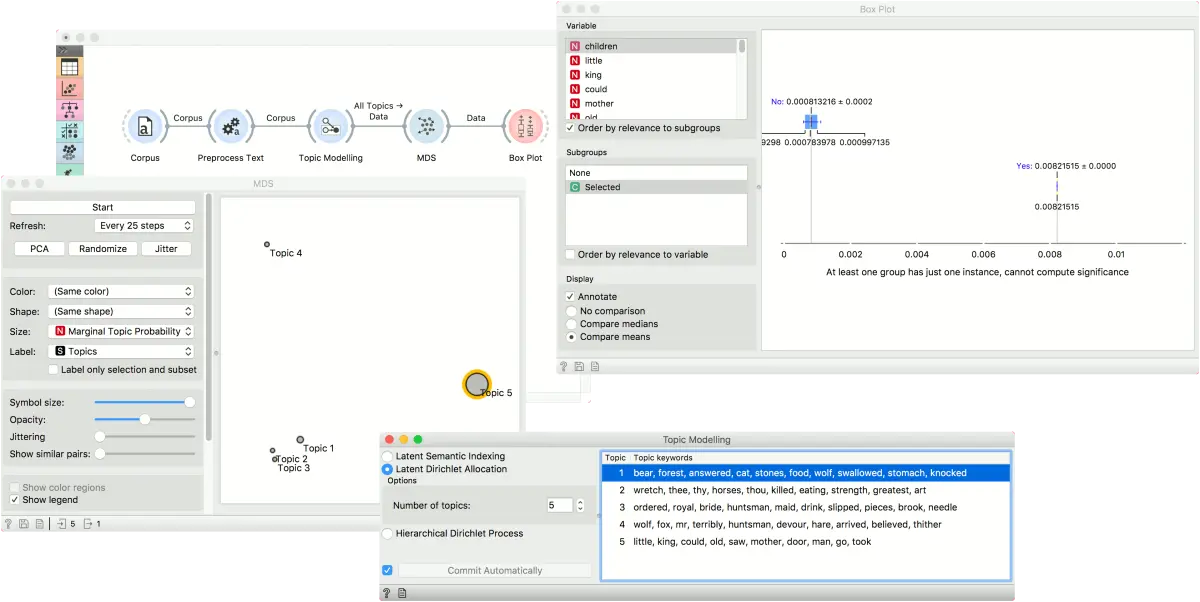
我们现在可以探究一下,哪些词是这个话题的代表词。比如说,从图中选择话题5,并将多维尺度分析连接到箱线图。确保输出设置为数据 –> 数据。
在箱线图中,将子组设置为 Selected,并选中 Order by relevance to subgroups 框。这个选项将根据变量在所选子组值之间的分离程度进行排序。在我们的案例中,这意味着哪些词对我们在图中选择的主题最有代表性(子组是指选定)。
我们可以看到,little、children和 kings 是 topic 5 最具代表性的单词,这个话题的词频与其他所有话题的词频分离度很好。在多维尺度分析中选择其他话题,看看框图的变化。
反馈问题
文档有问题? 或者有其他意见和建议? 请在本文档的 Github 仓库直接反馈
点我反馈进入反馈页面不知道如何反馈, 请点击这里