词充实(Word Enrichment)
对选定的文件进行词语丰富性分析。
投入。
- 语料库: 一系列文件。
- 选定数据:从语料库中选取的实例。从语料库中选出的实例。
功能
词充实(Word Enrichment)显示与整个语料库相比,选定子集的p值较低(显著性较高)的单词列表。较低的p值表示该词对所选子集有较高的可能性(不是随机出现在文本中)。FDR(False Discovery Rate,错误发现率)与p值相关联,报告预测集中错误预测的预期百分比,意味着它占低p值列表中的假阳性。
界面
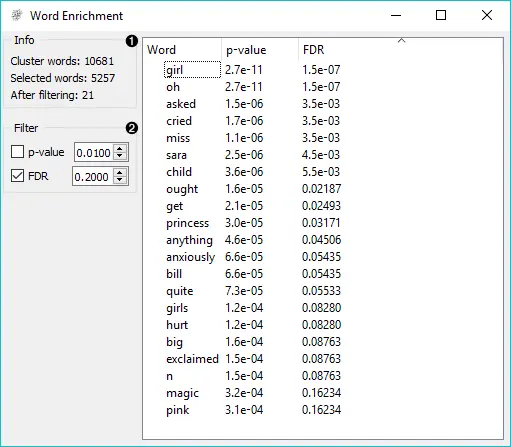
- 输入的信息。
- 集群词是指语料库中的所有词。
- 选取词为所选子集中的所有标记。
- 经过过滤后报告在子集中发现的充实后的词。
- 过滤可以通过以下方式进行过滤。
示例
在下面的例子中,我们检索的是2016年总统候选人唐纳德-特朗普和希拉里-克林顿的近期推文。然后我们对这些推文进行了预处理,只得到单词作为标记,并去除停顿词。我们将预处理后的语料连接到词袋,得到我们语料的字数表。
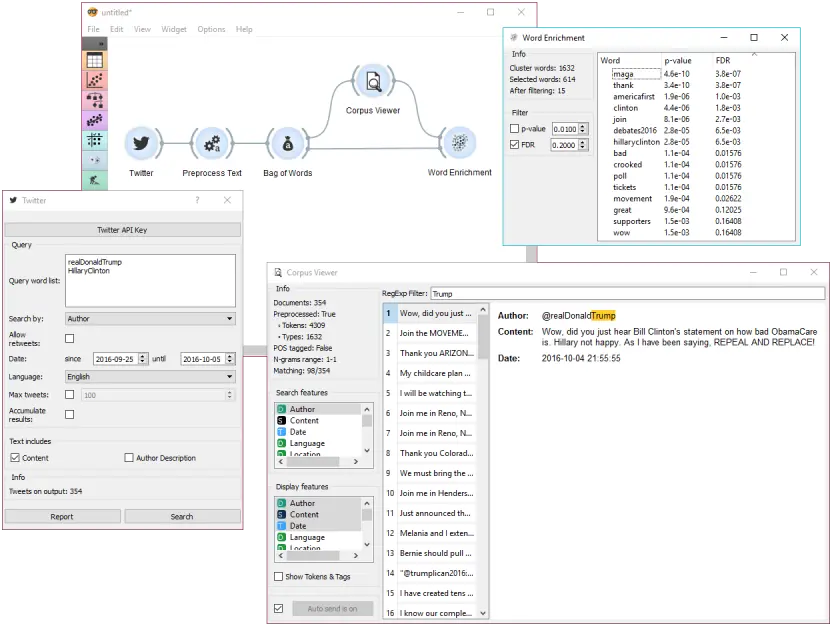
然后我们将语料查看器连接到词袋,只选择那些由唐纳德-特朗普发布的推文。请看我们如何只标记作者作为我们的搜索功能来检索这些推文。
词充实(Word Enrichment)接受两个输入–整个语料库作为参考,以及从语料库中选择一个子集来做丰富。首先将语料查看器连接到词充实(Word Enrichment)(输入 Matching Docs → Selected Data),然后将词袋 连接到它(输入 Corpus → Data)。在词充实(Word Enrichment)小工具中,我们可以看到对唐纳德-特朗普比对希拉里-克林顿更重要的单词列表。
反馈问题
文档有问题? 或者有其他意见和建议? 请在本文档的 Github 仓库直接反馈
点我反馈进入反馈页面不知道如何反馈, 请点击这里